 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVidLaDA: Bidirectional Diffusion Large Language Models for Efficient Video Understanding
Jan 25, 2026Standard Autoregressive Video LLMs inevitably suffer from causal masking biases that hinder global spatiotemporal modeling, leading to suboptimal understanding efficiency. We propose VidLaDA, a Video LLM based on Diffusion Language Model utilizing bidirectional attention to capture bidirectional dependencies. To further tackle the inference bottleneck of diffusion decoding on massive video tokens, we introduce MARS-Cache. This framework accelerates inference by combining asynchronous visual cache refreshing with frame-wise chunk attention, effectively pruning redundancy while preserving global connectivity via anchor tokens. Extensive experiments show VidLaDA outperforms diffusion baselines and rivals state-of-the-art autoregressive models (e.g., Qwen2.5-VL and LLaVA-Video), with MARS-Cache delivering over 12x speedup without compromising reasoning accuracy. Code and checkpoints are open-sourced at https://github.com/ziHoHe/VidLaDA.
Enhancing Video Large Language Models with Structured Multi-Video Collaborative Reasoning (early version)
Sep 16, 2025Despite the prosperity of the video language model, the current pursuit of comprehensive video reasoning is thwarted by the inherent spatio-temporal incompleteness within individual videos, resulting in hallucinations and inaccuracies. A promising solution is to augment the reasoning performance with multiple related videos. However, video tokens are numerous and contain redundant information, so directly feeding the relevant video data into a large language model to enhance responses could be counterproductive. To address this challenge, we propose a multi-video collaborative framework for video language models. For efficient and flexible video representation, we establish a Video Structuring Module to represent the video's knowledge as a spatio-temporal graph. Based on the structured video representation, we design the Graph Fusion Module to fuse the structured knowledge and valuable information from related videos into the augmented graph node tokens. Finally, we construct an elaborate multi-video structured prompt to integrate the graph, visual, and textual tokens as the input to the large language model. Extensive experiments substantiate the effectiveness of our framework, showcasing its potential as a promising avenue for advancing video language models.
Rodimus*: Breaking the Accuracy-Efficiency Trade-Off with Efficient Attentions
Oct 09, 2024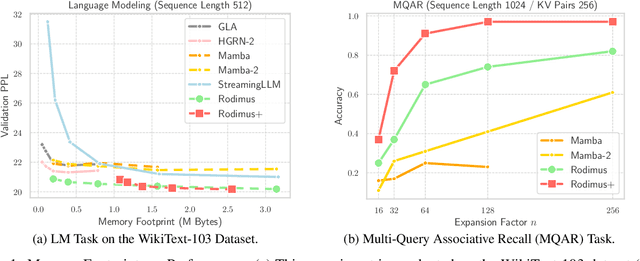
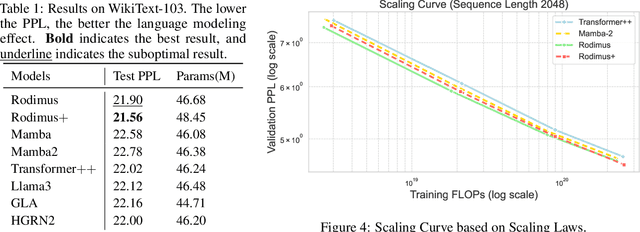
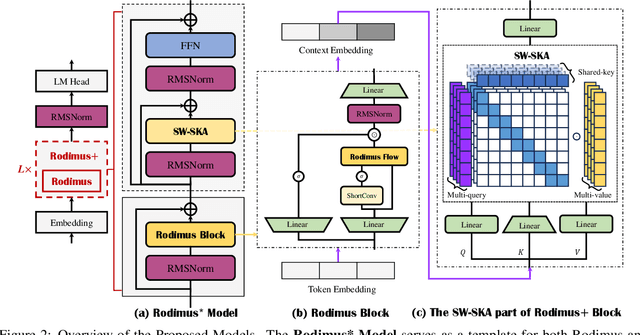
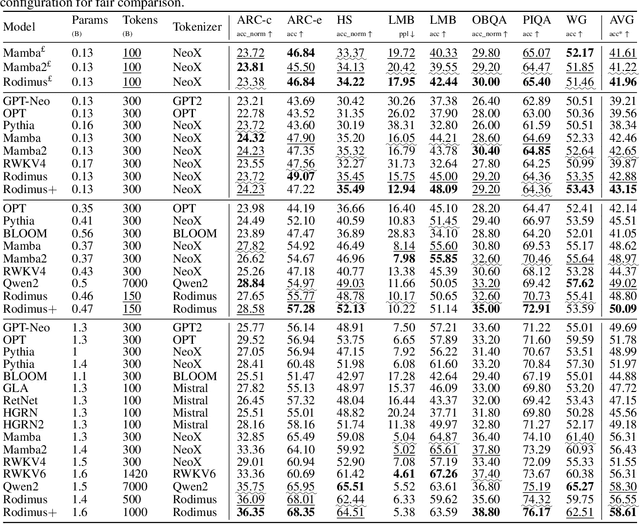
Recent advancements in Transformer-based large language models (LLMs) have set new standards in natural language processing. However, the classical softmax attention incurs significant computational costs, leading to a $O(T)$ complexity for per-token generation, where $T$ represents the context length. This work explores reducing LLMs' complexity while maintaining performance by introducing Rodimus and its enhanced version, Rodimus$+$. Rodimus employs an innovative data-dependent tempered selection (DDTS) mechanism within a linear attention-based, purely recurrent framework, achieving significant accuracy while drastically reducing the memory usage typically associated with recurrent models. This method exemplifies semantic compression by maintaining essential input information with fixed-size hidden states. Building on this, Rodimus$+$ combines Rodimus with the innovative Sliding Window Shared-Key Attention (SW-SKA) in a hybrid approach, effectively leveraging the complementary semantic, token, and head compression techniques. Our experiments demonstrate that Rodimus$+$-1.6B, trained on 1 trillion tokens, achieves superior downstream performance against models trained on more tokens, including Qwen2-1.5B and RWKV6-1.6B, underscoring its potential to redefine the accuracy-efficiency balance in LLMs. Model code and pre-trained checkpoints will be available soon.