 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistillation Learning Guided by Image Reconstruction for One-Shot Medical Image Segmentation
Aug 07, 2024



Traditional one-shot medical image segmentation (MIS) methods use registration networks to propagate labels from a reference atlas or rely on comprehensive sampling strategies to generate synthetic labeled data for training. However, these methods often struggle with registration errors and low-quality synthetic images, leading to poor performance and generalization. To overcome this, we introduce a novel one-shot MIS framework based on knowledge distillation, which allows the network to directly 'see' real images through a distillation process guided by image reconstruction. It focuses on anatomical structures in a single labeled image and a few unlabeled ones. A registration-based data augmentation network creates realistic, labeled samples, while a feature distillation module helps the student network learn segmentation from these samples, guided by the teacher network. During inference, the streamlined student network accurately segments new images. Evaluations on three public datasets (OASIS for T1 brain MRI, BCV for abdomen CT, and VerSe for vertebrae CT) show superior segmentation performance and generalization across different medical image datasets and modalities compared to leading methods. Our code is available at https://github.com/NoviceFodder/OS-MedSeg.
Supervising the Decoder of Variational Autoencoders to Improve Scientific Utility
Sep 09, 2021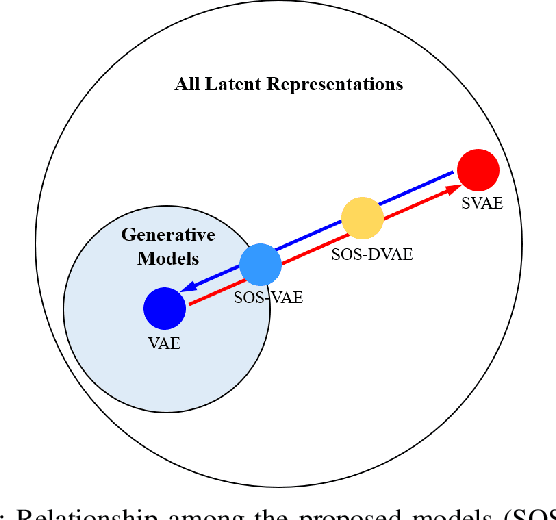
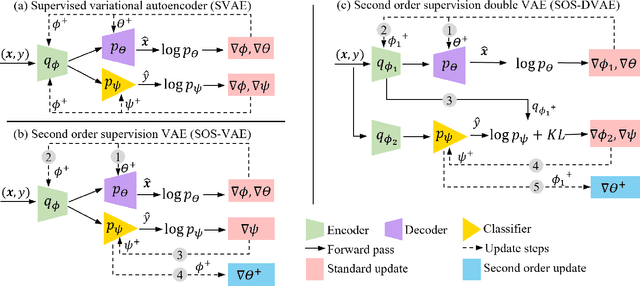
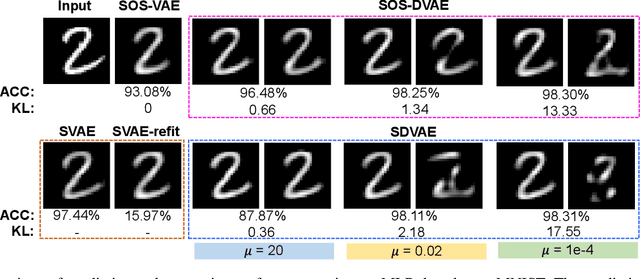
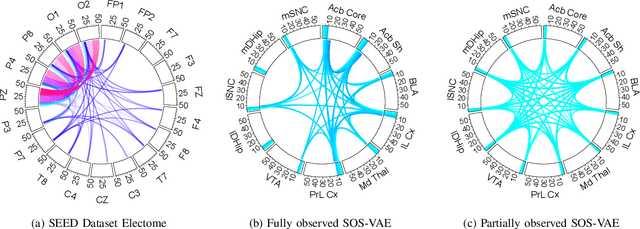
Probabilistic generative models are attractive for scientific modeling because their inferred parameters can be used to generate hypotheses and design experiments. This requires that the learned model provide an accurate representation of the input data and yield a latent space that effectively predicts outcomes relevant to the scientific question. Supervised Variational Autoencoders (SVAEs) have previously been used for this purpose, where a carefully designed decoder can be used as an interpretable generative model while the supervised objective ensures a predictive latent representation. Unfortunately, the supervised objective forces the encoder to learn a biased approximation to the generative posterior distribution, which renders the generative parameters unreliable when used in scientific models. This issue has remained undetected as reconstruction losses commonly used to evaluate model performance do not detect bias in the encoder. We address this previously-unreported issue by developing a second order supervision framework (SOS-VAE) that influences the decoder to induce a predictive latent representation. This ensures that the associated encoder maintains a reliable generative interpretation. We extend this technique to allow the user to trade-off some bias in the generative parameters for improved predictive performance, acting as an intermediate option between SVAEs and our new SOS-VAE. We also use this methodology to address missing data issues that often arise when combining recordings from multiple scientific experiments. We demonstrate the effectiveness of these developments using synthetic data and electrophysiological recordings with an emphasis on how our learned representations can be used to design scientific experiments.