 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePedicle Screw Pairing and Registration for Screw Pose Estimation from Dual C-arm Images Using CAD Models
Nov 07, 2025Accurate matching of pedicle screws in both anteroposterior (AP) and lateral (LAT) images is critical for successful spinal decompression and stabilization during surgery. However, establishing screw correspondence, especially in LAT views, remains a significant clinical challenge. This paper introduces a method to address pedicle screw correspondence and pose estimation from dual C-arm images. By comparing screw combinations, the approach demonstrates consistent accuracy in both pairing and registration tasks. The method also employs 2D-3D alignment with screw CAD 3D models to accurately pair and estimate screw pose from dual views. Our results show that the correct screw combination consistently outperforms incorrect pairings across all test cases, even prior to registration. After registration, the correct combination further enhances alignment between projections and images, significantly reducing projection error. This approach shows promise for improving surgical outcomes in spinal procedures by providing reliable feedback on screw positioning.
Robust Single-view Cone-beam X-ray Pose Estimation with Neural Tuned Tomography and Masked Neural Radiance Fields
Aug 18, 2023Many tasks performed in image-guided, mini-invasive, medical procedures can be cast as pose estimation problems, where an X-ray projection is utilized to reach a target in 3D space. Expanding on recent advances in the differentiable rendering of optically reflective materials, we introduce new methods for pose estimation of radiolucent objects using X-ray projections, and we demonstrate the critical role of optimal view synthesis in performing this task. We first develop an algorithm (DiffDRR) that efficiently computes Digitally Reconstructed Radiographs (DRRs) and leverages automatic differentiation within TensorFlow. Pose estimation is performed by iterative gradient descent using a loss function that quantifies the similarity of the DRR synthesized from a randomly initialized pose and the true fluoroscopic image at the target pose. We propose two novel methods for high-fidelity view synthesis, Neural Tuned Tomography (NeTT) and masked Neural Radiance Fields (mNeRF). Both methods rely on classic Cone-Beam Computerized Tomography (CBCT); NeTT directly optimizes the CBCT densities, while the non-zero values of mNeRF are constrained by a 3D mask of the anatomic region segmented from CBCT. We demonstrate that both NeTT and mNeRF distinctly improve pose estimation within our framework. By defining a successful pose estimate to be a 3D angle error of less than 3 deg, we find that NeTT and mNeRF can achieve similar results, both with overall success rates more than 93%. However, the computational cost of NeTT is significantly lower than mNeRF in both training and pose estimation. Furthermore, we show that a NeTT trained for a single subject can generalize to synthesize high-fidelity DRRs and ensure robust pose estimations for all other subjects. Therefore, we suggest that NeTT is an attractive option for robust pose estimation using fluoroscopic projections.
Text2Struct: A Machine Learning Pipeline for Mining Structured Data from Text
Dec 20, 2022


Many analysis and prediction tasks require the extraction of structured data from unstructured texts. To solve it, this paper presents an end-to-end machine learning pipeline, Text2Struct, including a text annotation scheme, training data processing, and machine learning implementation. We formulated the mining problem as the extraction of metrics and units associated with numerals in the text. The Text2Struct was evaluated on an annotated text dataset collected from abstracts of medical publications regarding thrombectomy. In terms of prediction performance, a dice coefficient of 0.82 was achieved on the test dataset. By random sampling, most predicted relations between numerals and entities were well matched to the ground-truth annotations. These results show that the Text2Struct is viable for the mining of structured data from text without special templates or patterns. It is anticipated to further improve the pipeline by expanding the dataset and investigating other machine learning models. A code demonstration can be found at: https://github.com/zcc861007/CourseProject
Transfer Learning from an Artificial Radiograph-landmark Dataset for Registration of the Anatomic Skull Model to Dual Fluoroscopic X-ray Images
Aug 14, 2021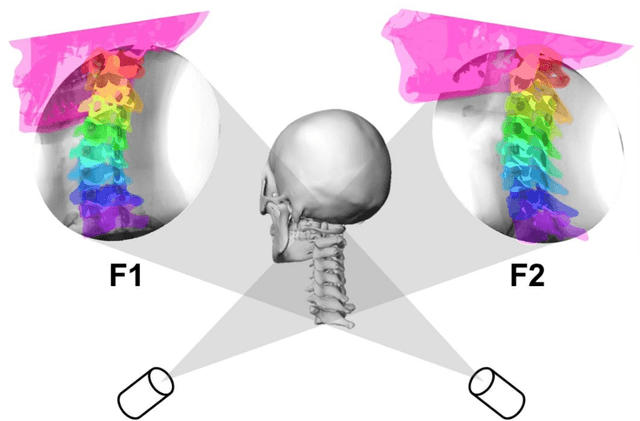

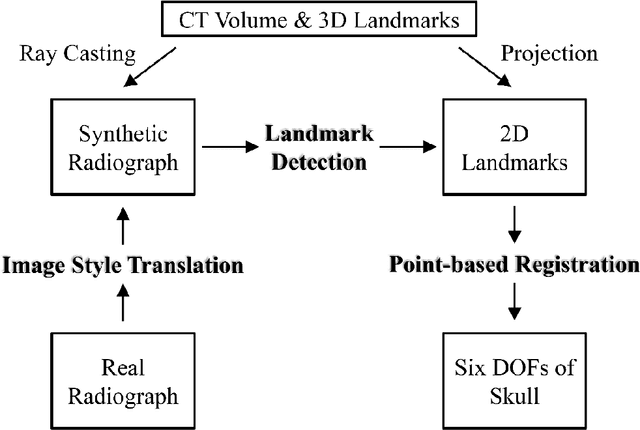
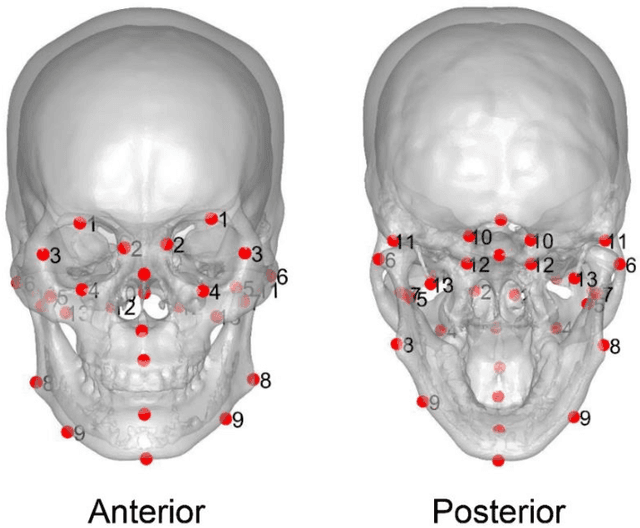
Registration of 3D anatomic structures to their 2D dual fluoroscopic X-ray images is a widely used motion tracking technique. However, deep learning implementation is often impeded by a paucity of medical images and ground truths. In this study, we proposed a transfer learning strategy for 3D-to-2D registration using deep neural networks trained from an artificial dataset. Digitally reconstructed radiographs (DRRs) and radiographic skull landmarks were automatically created from craniocervical CT data of a female subject. They were used to train a residual network (ResNet) for landmark detection and a cycle generative adversarial network (GAN) to eliminate the style difference between DRRs and actual X-rays. Landmarks on the X-rays experiencing GAN style translation were detected by the ResNet, and were used in triangulation optimization for 3D-to-2D registration of the skull in actual dual-fluoroscope images (with a non-orthogonal setup, point X-ray sources, image distortions, and partially captured skull regions). The registration accuracy was evaluated in multiple scenarios of craniocervical motions. In walking, learning-based registration for the skull had angular/position errors of 3.9 +- 2.1 deg / 4.6 +- 2.2 mm. However, the accuracy was lower during functional neck activity, due to overly small skull regions imaged on the dual fluoroscopic images at end-range positions. The methodology to strategically augment artificial training data can tackle the complicated skull registration scenario, and has potentials to extend to widespread registration scenarios.