 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Fair and Explainable AI using a Human-Centered AI Approach
Jun 12, 2023The rise of machine learning (ML) is accompanied by several high-profile cases that have stressed the need for fairness, accountability, explainability and trust in ML systems. The existing literature has largely focused on fully automated ML approaches that try to optimize for some performance metric. However, human-centric measures like fairness, trust, explainability, etc. are subjective in nature, context-dependent, and might not correlate with conventional performance metrics. To deal with these challenges, we explore a human-centered AI approach that empowers people by providing more transparency and human control. In this dissertation, we present 5 research projects that aim to enhance explainability and fairness in classification systems and word embeddings. The first project explores the utility/downsides of introducing local model explanations as interfaces for machine teachers (crowd workers). Our study found that adding explanations supports trust calibration for the resulting ML model and enables rich forms of teaching feedback. The second project presents D-BIAS, a causality-based human-in-the-loop visual tool for identifying and mitigating social biases in tabular datasets. Apart from fairness, we found that our tool also enhances trust and accountability. The third project presents WordBias, a visual interactive tool that helps audit pre-trained static word embeddings for biases against groups, such as females, or subgroups, such as Black Muslim females. The fourth project presents DramatVis Personae, a visual analytics tool that helps identify social biases in creative writing. Finally, the last project presents an empirical study aimed at understanding the cumulative impact of multiple fairness-enhancing interventions at different stages of the ML pipeline on fairness, utility and different population groups. We conclude by discussing some of the future directions.
D-BIAS: A Causality-Based Human-in-the-Loop System for Tackling Algorithmic Bias
Aug 10, 2022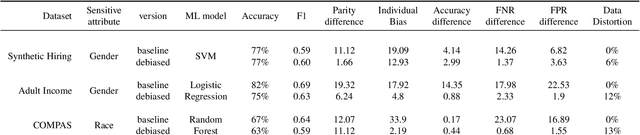
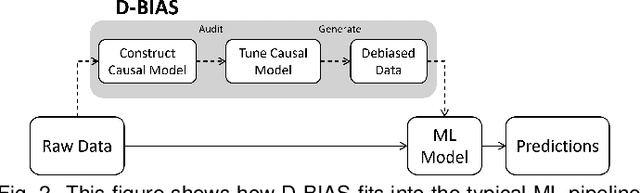

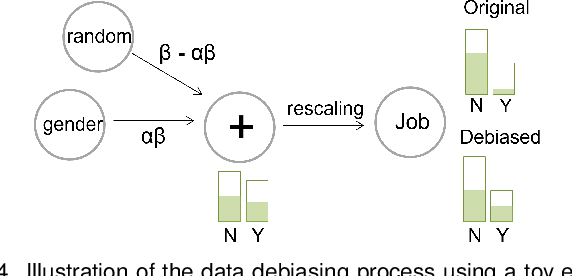
With the rise of AI, algorithms have become better at learning underlying patterns from the training data including ingrained social biases based on gender, race, etc. Deployment of such algorithms to domains such as hiring, healthcare, law enforcement, etc. has raised serious concerns about fairness, accountability, trust and interpretability in machine learning algorithms. To alleviate this problem, we propose D-BIAS, a visual interactive tool that embodies human-in-the-loop AI approach for auditing and mitigating social biases from tabular datasets. It uses a graphical causal model to represent causal relationships among different features in the dataset and as a medium to inject domain knowledge. A user can detect the presence of bias against a group, say females, or a subgroup, say black females, by identifying unfair causal relationships in the causal network and using an array of fairness metrics. Thereafter, the user can mitigate bias by acting on the unfair causal edges. For each interaction, say weakening/deleting a biased causal edge, the system uses a novel method to simulate a new (debiased) dataset based on the current causal model. Users can visually assess the impact of their interactions on different fairness metrics, utility metrics, data distortion, and the underlying data distribution. Once satisfied, they can download the debiased dataset and use it for any downstream application for fairer predictions. We evaluate D-BIAS by conducting experiments on 3 datasets and also a formal user study. We found that D-BIAS helps reduce bias significantly compared to the baseline debiasing approach across different fairness metrics while incurring little data distortion and a small loss in utility. Moreover, our human-in-the-loop based approach significantly outperforms an automated approach on trust, interpretability and accountability.
Cascaded Debiasing : Studying the Cumulative Effect of Multiple Fairness-Enhancing Interventions
Feb 08, 2022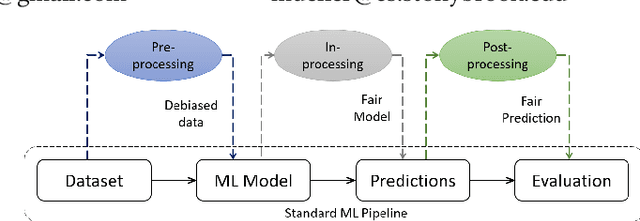


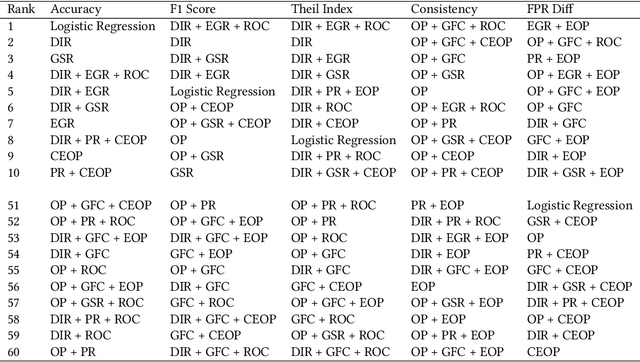
Understanding the cumulative effect of multiple fairness enhancing interventions at different stages of the machine learning (ML) pipeline is a critical and underexplored facet of the fairness literature. Such knowledge can be valuable to data scientists/ML practitioners in designing fair ML pipelines. This paper takes the first step in exploring this area by undertaking an extensive empirical study comprising 60 combinations of interventions, 9 fairness metrics, 2 utility metrics (Accuracy and F1 Score) across 4 benchmark datasets. We quantitatively analyze the experimental data to measure the impact of multiple interventions on fairness, utility and population groups. We found that applying multiple interventions results in better fairness and lower utility than individual interventions on aggregate. However, adding more interventions do no always result in better fairness or worse utility. The likelihood of achieving high performance (F1 Score) along with high fairness increases with larger number of interventions. On the downside, we found that fairness-enhancing interventions can negatively impact different population groups, especially the privileged group. This study highlights the need for new fairness metrics that account for the impact on different population groups apart from just the disparity between groups. Lastly, we offer a list of combinations of interventions that perform best for different fairness and utility metrics to aid the design of fair ML pipelines.
Fluent: An AI Augmented Writing Tool for People who Stutter
Aug 23, 2021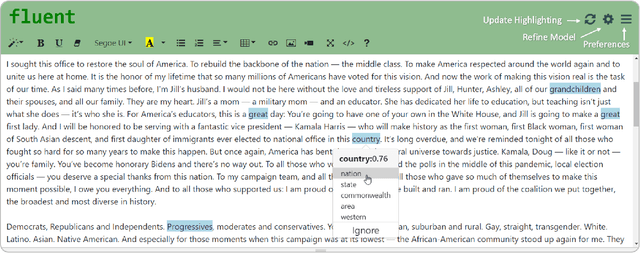
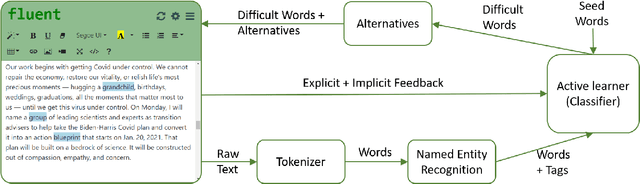
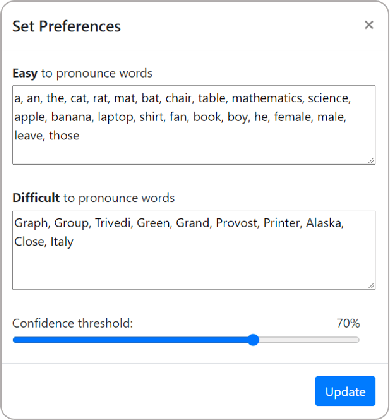
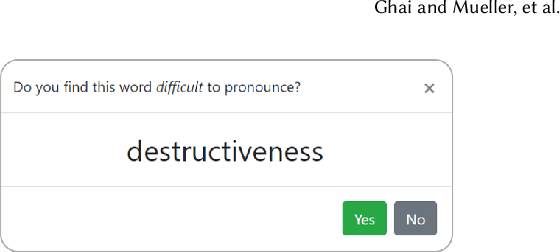
Stuttering is a speech disorder which impacts the personal and professional lives of millions of people worldwide. To save themselves from stigma and discrimination, people who stutter (PWS) may adopt different strategies to conceal their stuttering. One of the common strategies is word substitution where an individual avoids saying a word they might stutter on and use an alternative instead. This process itself can cause stress and add more burden. In this work, we present Fluent, an AI augmented writing tool which assists PWS in writing scripts which they can speak more fluently. Fluent embodies a novel active learning based method of identifying words an individual might struggle pronouncing. Such words are highlighted in the interface. On hovering over any such word, Fluent presents a set of alternative words which have similar meaning but are easier to speak. The user is free to accept or ignore these suggestions. Based on such user interaction (feedback), Fluent continuously evolves its classifier to better suit the personalized needs of each user. We evaluated our tool by measuring its ability to identify difficult words for 10 simulated users. We found that our tool can identify difficult words with a mean accuracy of over 80% in under 20 interactions and it keeps improving with more feedback. Our tool can be beneficial for certain important life situations like giving a talk, presentation, etc. The source code for this tool has been made publicly accessible at github.com/bhavyaghai/Fluent.
WordBias: An Interactive Visual Tool for Discovering Intersectional Biases Encoded in Word Embeddings
Mar 05, 2021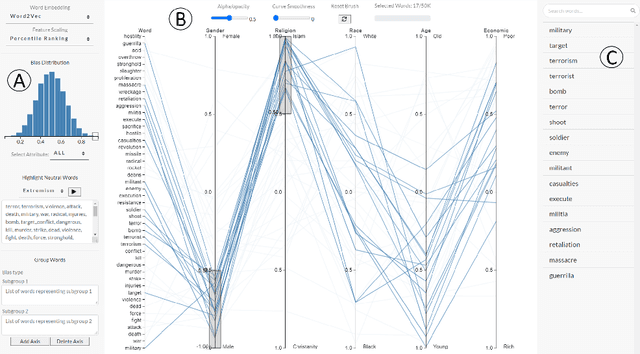
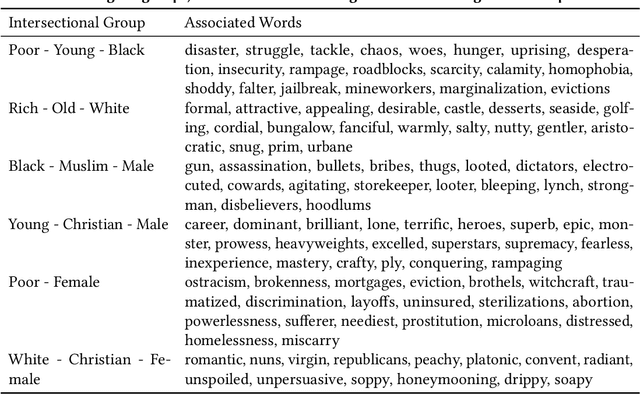
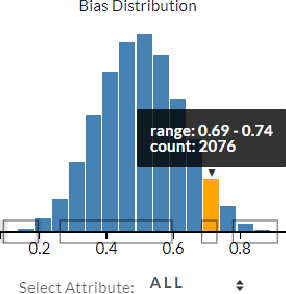
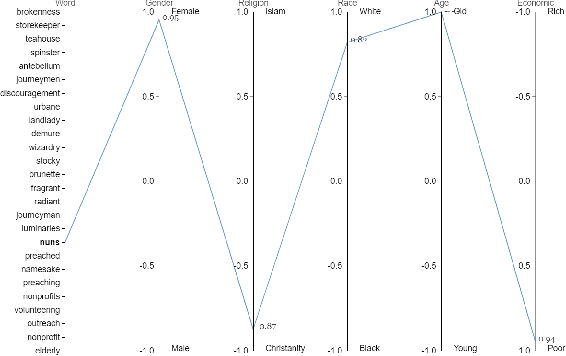
Intersectional bias is a bias caused by an overlap of multiple social factors like gender, sexuality, race, disability, religion, etc. A recent study has shown that word embedding models can be laden with biases against intersectional groups like African American females, etc. The first step towards tackling such intersectional biases is to identify them. However, discovering biases against different intersectional groups remains a challenging task. In this work, we present WordBias, an interactive visual tool designed to explore biases against intersectional groups encoded in static word embeddings. Given a pretrained static word embedding, WordBias computes the association of each word along different groups based on race, age, etc. and then visualizes them using a novel interactive interface. Using a case study, we demonstrate how WordBias can help uncover biases against intersectional groups like Black Muslim Males, Poor Females, etc. encoded in word embedding. In addition, we also evaluate our tool using qualitative feedback from expert interviews. The source code for this tool can be publicly accessed for reproducibility at github.com/bhavyaghai/WordBias.
Active Learning++: Incorporating Annotator's Rationale using Local Model Explanation
Sep 06, 2020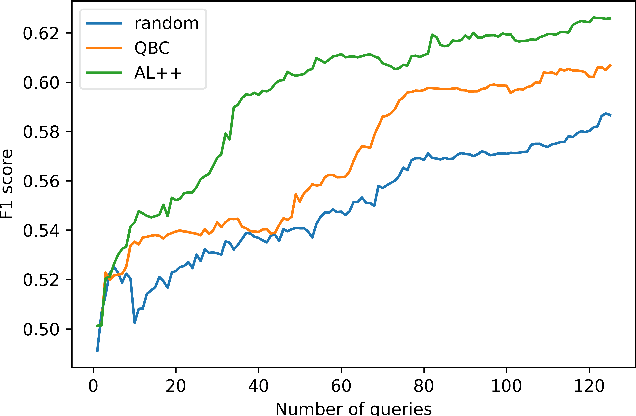
We propose a new active learning (AL) framework, Active Learning++, which can utilize an annotator's labels as well as its rationale. Annotators can provide their rationale for choosing a label by ranking input features based on their importance for a given query. To incorporate this additional input, we modified the disagreement measure for a bagging-based Query by Committee (QBC) sampling strategy. Instead of weighing all committee models equally to select the next instance, we assign higher weight to the committee model with higher agreement with the annotator's ranking. Specifically, we generated a feature importance-based local explanation for each committee model. The similarity score between feature rankings provided by the annotator and the local model explanation is used to assign a weight to each corresponding committee model. This approach is applicable to any kind of ML model using model-agnostic techniques to generate local explanation such as LIME. With a simulation study, we show that our framework significantly outperforms a QBC based vanilla AL framework.
Measuring Social Biases of Crowd Workers using Counterfactual Queries
Apr 04, 2020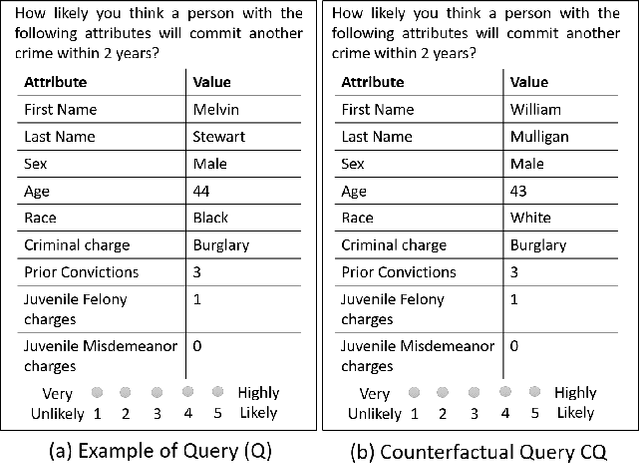
Social biases based on gender, race, etc. have been shown to pollute machine learning (ML) pipeline predominantly via biased training datasets. Crowdsourcing, a popular cost-effective measure to gather labeled training datasets, is not immune to the inherent social biases of crowd workers. To ensure such social biases aren't passed onto the curated datasets, it's important to know how biased each crowd worker is. In this work, we propose a new method based on counterfactual fairness to quantify the degree of inherent social bias in each crowd worker. This extra information can be leveraged together with individual worker responses to curate a less biased dataset.
Explainable Active Learning (XAL): An Empirical Study of How Local Explanations Impact Annotator Experience
Jan 31, 2020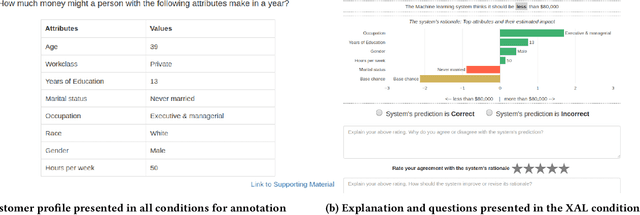
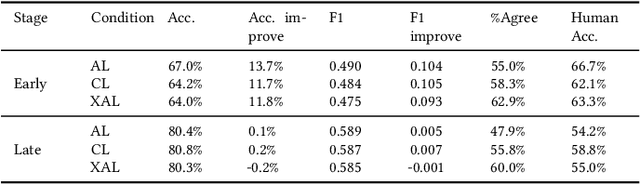
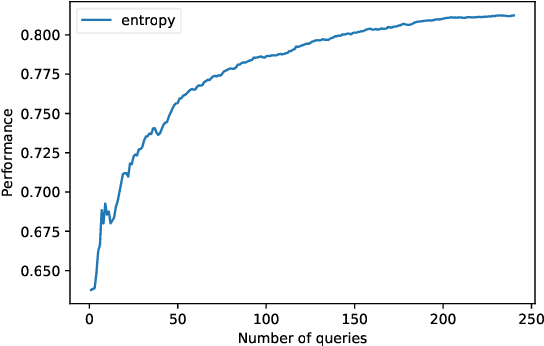
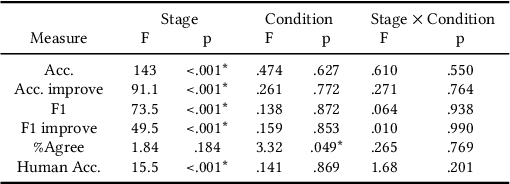
Active Learning (AL) is a human-in-the-loop Machine Learning paradigm favored for its ability to learn with fewer labeled instances, but the model's states and progress remain opaque to the annotators. Meanwhile, many recognize the benefits of model transparency for people interacting with ML models, as reflected by the surge of explainable AI (XAI) as a research field. However, explaining an evolving model introduces many open questions regarding its impact on the annotation quality and the annotator's experience. In this paper, we propose a novel paradigm of explainable active learning (XAL), by explaining the learning algorithm's prediction for the instance it wants to learn from and soliciting feedback from the annotator. We conduct an empirical study comparing the model learning outcome, human feedback content and the annotator experience with XAL, to that of traditional AL and coactive learning (providing the model's prediction without the explanation). Our study reveals benefits--supporting trust calibration and enabling additional forms of human feedback, and potential drawbacks--anchoring effect and frustration from transparent model limitations--of providing local explanations in AL. We conclude by suggesting directions for developing explanations that better support annotator experience in AL and interactive ML settings.
Does Speech enhancement of publicly available data help build robust Speech Recognition Systems?
Nov 20, 2019
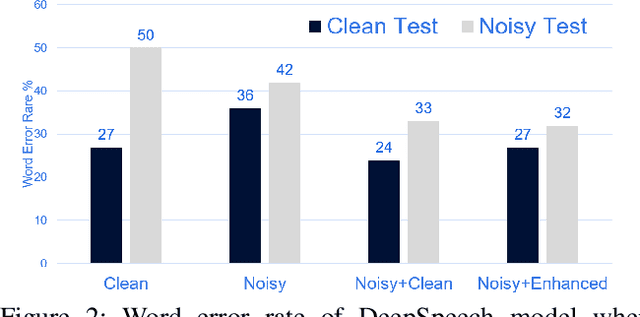
Automatic speech recognition (ASR) systems play a key role in many commercial products including voice assistants. Typically, they require large amounts of clean speech data for training which gives an undue advantage to large organizations which have tons of private data. In this paper, we have first curated a fairly big dataset using publicly available data sources. Thereafter, we tried to investigate if we can use publicly available noisy data to train robust ASR systems. We have used speech enhancement to clean the noisy data first and then used it together with its cleaned version to train ASR systems. We have found that using speech enhancement gives 9.5\% better word error rate than training on just noisy data and 9\% better than training on just clean data. It's performance is also comparable to the ideal case scenario when trained on noisy and its clean version.