 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Active Learning (XAL): An Empirical Study of How Local Explanations Impact Annotator Experience
Paper and Code
Jan 31, 2020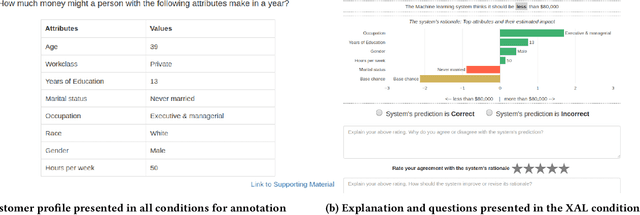
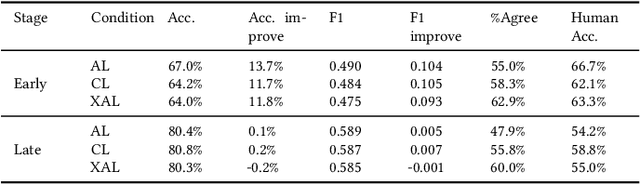
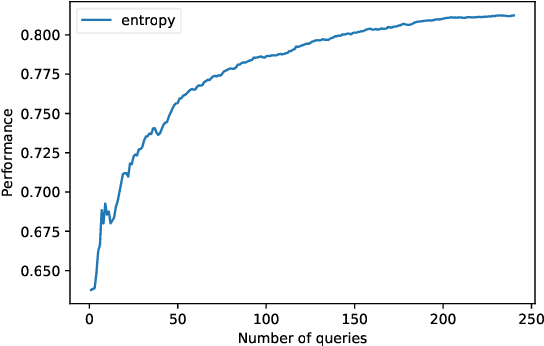
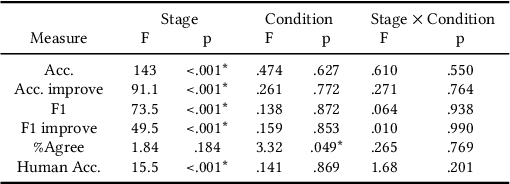
Active Learning (AL) is a human-in-the-loop Machine Learning paradigm favored for its ability to learn with fewer labeled instances, but the model's states and progress remain opaque to the annotators. Meanwhile, many recognize the benefits of model transparency for people interacting with ML models, as reflected by the surge of explainable AI (XAI) as a research field. However, explaining an evolving model introduces many open questions regarding its impact on the annotation quality and the annotator's experience. In this paper, we propose a novel paradigm of explainable active learning (XAL), by explaining the learning algorithm's prediction for the instance it wants to learn from and soliciting feedback from the annotator. We conduct an empirical study comparing the model learning outcome, human feedback content and the annotator experience with XAL, to that of traditional AL and coactive learning (providing the model's prediction without the explanation). Our study reveals benefits--supporting trust calibration and enabling additional forms of human feedback, and potential drawbacks--anchoring effect and frustration from transparent model limitations--of providing local explanations in AL. We conclude by suggesting directions for developing explanations that better support annotator experience in AL and interactive ML settings.