 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Synthetic Data Improves Multi-hop Reasoning
Mar 02, 2026Reinforcement Learning (RL) has been shown to significantly boost reasoning capabilities of large language models (LLMs) in math, coding, and multi-hop reasoning tasks. However, RL fine-tuning requires abundant high-quality verifiable data, often sourced from human annotations, generated from frontier LLMs, or scored by LLM-based verifiers. All three have considerable limitations: human-annotated datasets are small and expensive to curate, LLM-generated data is hallucination-prone and costly, and LLM-based verifiers are inaccurate and slow. In this work, we investigate a cheaper alternative: RL fine-tuning on rule-generated synthetic data for multi-hop reasoning tasks. We discover that LLMs fine-tuned on synthetic data perform significantly better on popular real-world question-answering benchmarks, despite the synthetic data containing only fictional knowledge. On stratifying performance by question difficulty, we find that synthetic data teaches LLMs to compose knowledge -- a fundamental and generalizable reasoning skill. Our work highlights rule-generated synthetic reasoning data as a free and scalable resource to improve LLM reasoning capabilities.
PhantomWiki: On-Demand Datasets for Reasoning and Retrieval Evaluation
Feb 27, 2025High-quality benchmarks are essential for evaluating reasoning and retrieval capabilities of large language models (LLMs). However, curating datasets for this purpose is not a permanent solution as they are prone to data leakage and inflated performance results. To address these challenges, we propose PhantomWiki: a pipeline to generate unique, factually consistent document corpora with diverse question-answer pairs. Unlike prior work, PhantomWiki is neither a fixed dataset, nor is it based on any existing data. Instead, a new PhantomWiki instance is generated on demand for each evaluation. We vary the question difficulty and corpus size to disentangle reasoning and retrieval capabilities respectively, and find that PhantomWiki datasets are surprisingly challenging for frontier LLMs. Thus, we contribute a scalable and data leakage-resistant framework for disentangled evaluation of reasoning, retrieval, and tool-use abilities. Our code is available at https://github.com/kilian-group/phantom-wiki.
AiSciVision: A Framework for Specializing Large Multimodal Models in Scientific Image Classification
Oct 28, 2024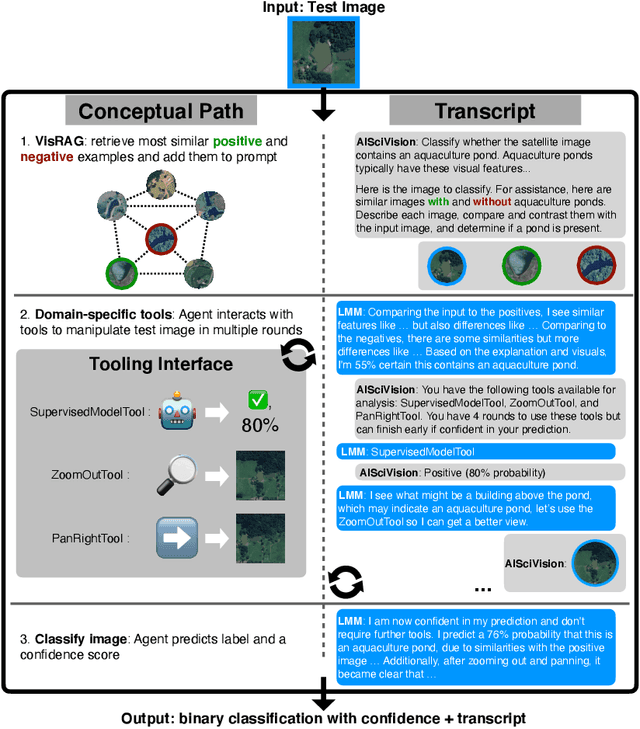



Trust and interpretability are crucial for the use of Artificial Intelligence (AI) in scientific research, but current models often operate as black boxes offering limited transparency and justifications for their outputs. We introduce AiSciVision, a framework that specializes Large Multimodal Models (LMMs) into interactive research partners and classification models for image classification tasks in niche scientific domains. Our framework uses two key components: (1) Visual Retrieval-Augmented Generation (VisRAG) and (2) domain-specific tools utilized in an agentic workflow. To classify a target image, AiSciVision first retrieves the most similar positive and negative labeled images as context for the LMM. Then the LMM agent actively selects and applies tools to manipulate and inspect the target image over multiple rounds, refining its analysis before making a final prediction. These VisRAG and tooling components are designed to mirror the processes of domain experts, as humans often compare new data to similar examples and use specialized tools to manipulate and inspect images before arriving at a conclusion. Each inference produces both a prediction and a natural language transcript detailing the reasoning and tool usage that led to the prediction. We evaluate AiSciVision on three real-world scientific image classification datasets: detecting the presence of aquaculture ponds, diseased eelgrass, and solar panels. Across these datasets, our method outperforms fully supervised models in low and full-labeled data settings. AiSciVision is actively deployed in real-world use, specifically for aquaculture research, through a dedicated web application that displays and allows the expert users to converse with the transcripts. This work represents a crucial step toward AI systems that are both interpretable and effective, advancing their use in scientific research and scientific discovery.
Score Design for Multi-Criteria Incentivization
Oct 08, 2024



We present a framework for designing scores to summarize performance metrics. Our design has two multi-criteria objectives: (1) improving on scores should improve all performance metrics, and (2) achieving pareto-optimal scores should achieve pareto-optimal metrics. We formulate our design to minimize the dimensionality of scores while satisfying the objectives. We give algorithms to design scores, which are provably minimal under mild assumptions on the structure of performance metrics. This framework draws motivation from real-world practices in hospital rating systems, where misaligned scores and performance metrics lead to unintended consequences.
The Limitations of Model Retraining in the Face of Performativity
Aug 16, 2024We study stochastic optimization in the context of performative shifts, where the data distribution changes in response to the deployed model. We demonstrate that naive retraining can be provably suboptimal even for simple distribution shifts. The issue worsens when models are retrained given a finite number of samples at each retraining step. We show that adding regularization to retraining corrects both of these issues, attaining provably optimal models in the face of distribution shifts. Our work advocates rethinking how machine learning models are retrained in the presence of performative effects.
Domain Private Transformers
May 23, 2023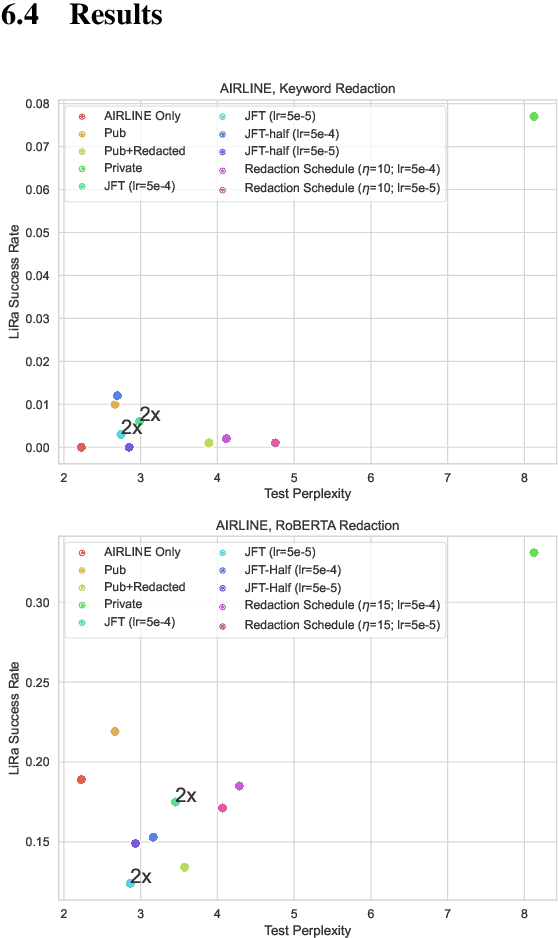
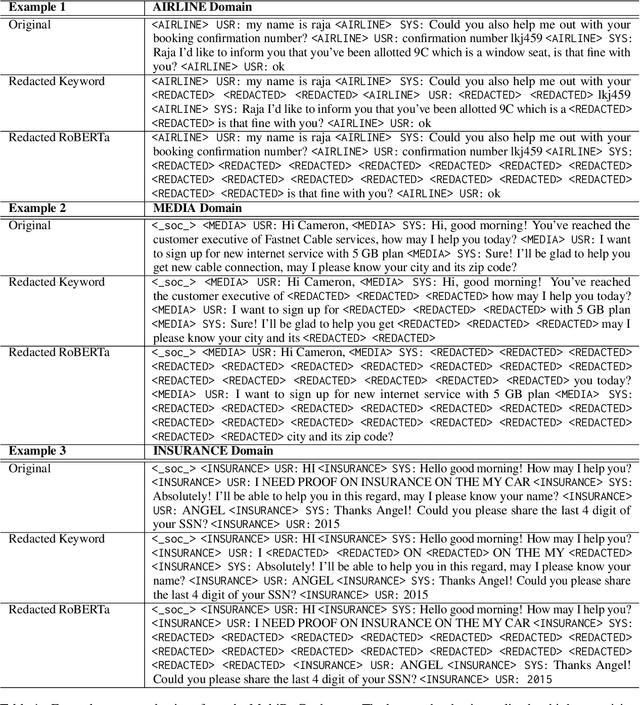
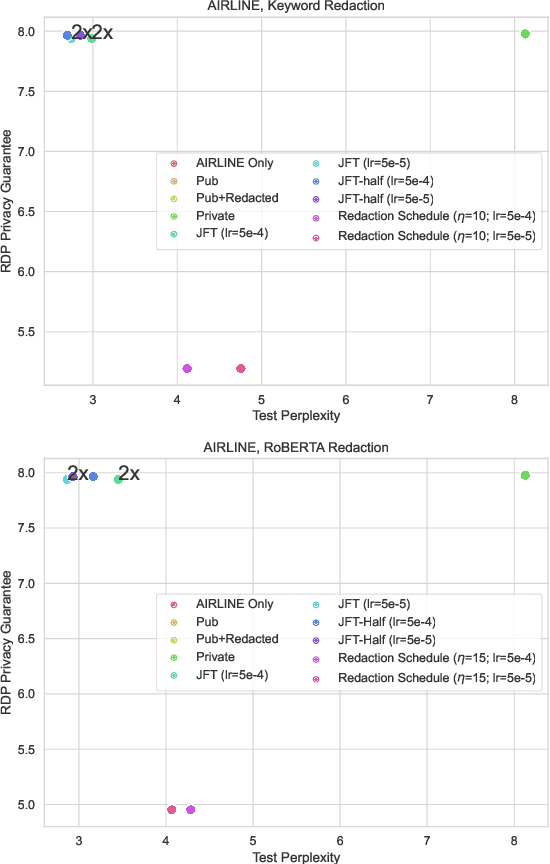
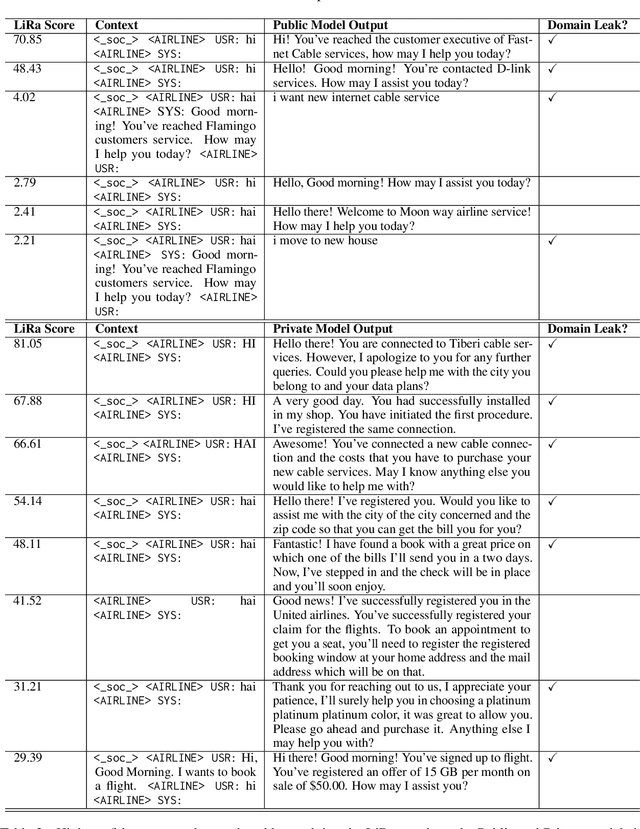
Large, general purpose language models have demonstrated impressive performance across many different conversational domains. While multi-domain language models achieve low overall perplexity, their outputs are not guaranteed to stay within the domain of a given input prompt. This paper proposes domain privacy as a novel way to quantify how likely a conditional language model will leak across domains. We also develop policy functions based on token-level domain classification, and propose an efficient fine-tuning method to improve the trained model's domain privacy. Experiments on membership inference attacks show that our proposed method has comparable resiliency to methods adapted from recent literature on differentially private language models.