 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabelKAN -- Kolmogorov-Arnold Networks for Inter-Label Learning: Avian Community Learning
Jan 23, 2026Global biodiversity loss is accelerating, prompting international efforts such as the Kunming-Montreal Global Biodiversity Framework (GBF) and the United Nations Sustainable Development Goals to direct resources toward halting species declines. A key challenge in achieving this goal is having access to robust methodologies to understand where species occur and how they relate to each other within broader ecological communities. Recent deep learning-based advances in joint species distribution modeling have shown improved predictive performance, but effectively incorporating community-level learning, taking into account species-species relationships in addition to species-environment relationships, remains an outstanding challenge. We introduce LabelKAN, a novel framework based on Kolmogorov-Arnold Networks (KANs) to learn inter-label connections from predictions of each label. When modeling avian species distributions, LabelKAN achieves substantial gains in predictive performance across the vast majority of species. In particular, our method demonstrates strong improvements for rare and difficult-to-predict species, which are often the most important when setting biodiversity targets under frameworks like GBF. These performance gains also translate to more confident predictions of the species spatial patterns as well as more confident predictions of community structure. We illustrate how the LabelKAN leads to qualitative and quantitative improvements with a focused application on the Great Blue Heron, an emblematic species in freshwater ecosystems that has experienced significant population declines across the United States in recent years. Using the LabelKAN framework, we are able to identify communities and species in New York that will be most sensitive to further declines in Great Blue Heron populations.
AiSciVision: A Framework for Specializing Large Multimodal Models in Scientific Image Classification
Oct 28, 2024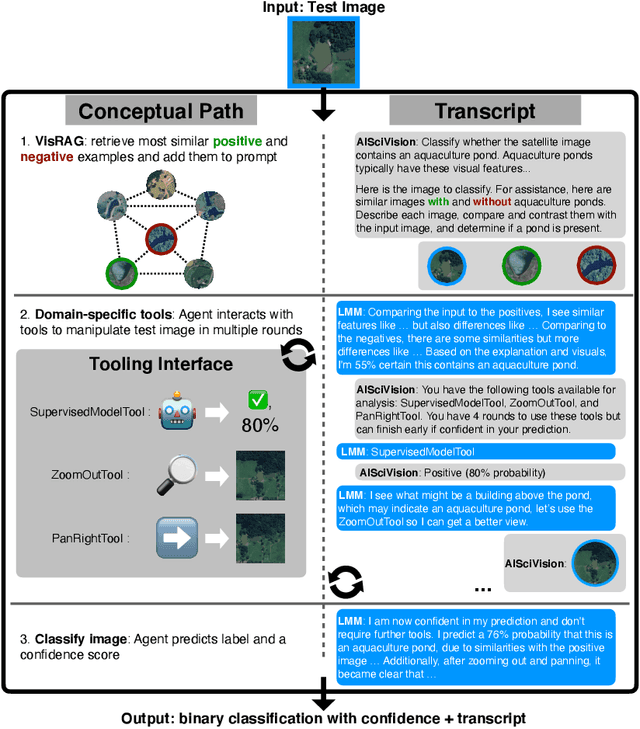



Trust and interpretability are crucial for the use of Artificial Intelligence (AI) in scientific research, but current models often operate as black boxes offering limited transparency and justifications for their outputs. We introduce AiSciVision, a framework that specializes Large Multimodal Models (LMMs) into interactive research partners and classification models for image classification tasks in niche scientific domains. Our framework uses two key components: (1) Visual Retrieval-Augmented Generation (VisRAG) and (2) domain-specific tools utilized in an agentic workflow. To classify a target image, AiSciVision first retrieves the most similar positive and negative labeled images as context for the LMM. Then the LMM agent actively selects and applies tools to manipulate and inspect the target image over multiple rounds, refining its analysis before making a final prediction. These VisRAG and tooling components are designed to mirror the processes of domain experts, as humans often compare new data to similar examples and use specialized tools to manipulate and inspect images before arriving at a conclusion. Each inference produces both a prediction and a natural language transcript detailing the reasoning and tool usage that led to the prediction. We evaluate AiSciVision on three real-world scientific image classification datasets: detecting the presence of aquaculture ponds, diseased eelgrass, and solar panels. Across these datasets, our method outperforms fully supervised models in low and full-labeled data settings. AiSciVision is actively deployed in real-world use, specifically for aquaculture research, through a dedicated web application that displays and allows the expert users to converse with the transcripts. This work represents a crucial step toward AI systems that are both interpretable and effective, advancing their use in scientific research and scientific discovery.
Monitoring Vegetation From Space at Extremely Fine Resolutions via Coarsely-Supervised Smooth U-Net
Jul 16, 2022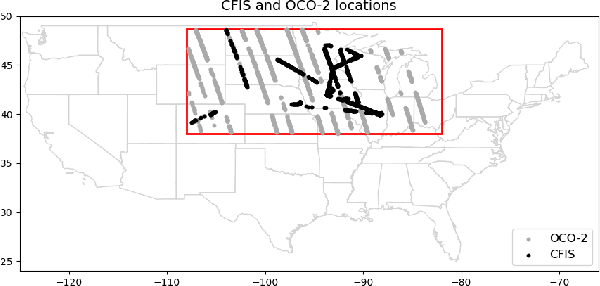
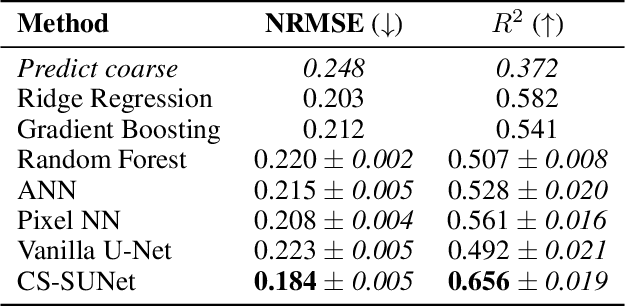
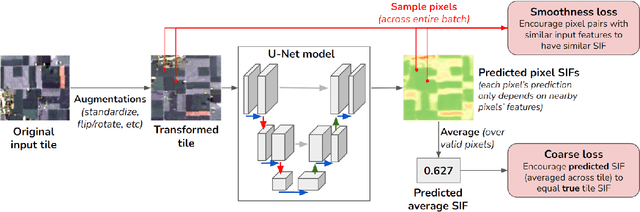
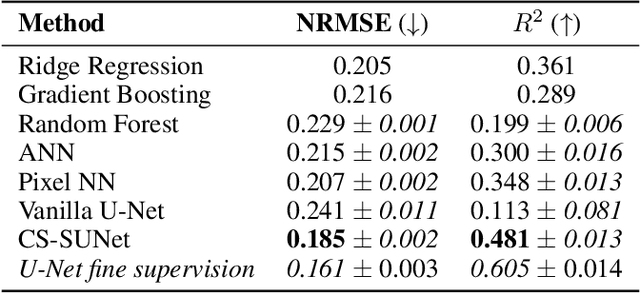
Monitoring vegetation productivity at extremely fine resolutions is valuable for real-world agricultural applications, such as detecting crop stress and providing early warning of food insecurity. Solar-Induced Chlorophyll Fluorescence (SIF) provides a promising way to directly measure plant productivity from space. However, satellite SIF observations are only available at a coarse spatial resolution, making it impossible to monitor how individual crop types or farms are doing. This poses a challenging coarsely-supervised regression (or downscaling) task; at training time, we only have SIF labels at a coarse resolution (3km), but we want to predict SIF at much finer spatial resolutions (e.g. 30m, a 100x increase). We also have additional fine-resolution input features, but the relationship between these features and SIF is unknown. To address this, we propose Coarsely-Supervised Smooth U-Net (CS-SUNet), a novel method for this coarse supervision setting. CS-SUNet combines the expressive power of deep convolutional networks with novel regularization methods based on prior knowledge (such as a smoothness loss) that are crucial for preventing overfitting. Experiments show that CS-SUNet resolves fine-grained variations in SIF more accurately than existing methods.
A GNN-RNN Approach for Harnessing Geospatial and Temporal Information: Application to Crop Yield Prediction
Nov 17, 2021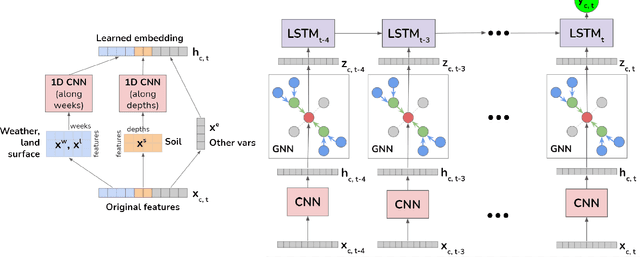
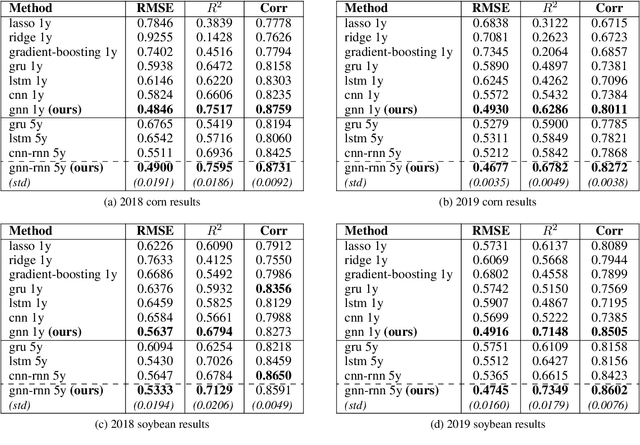
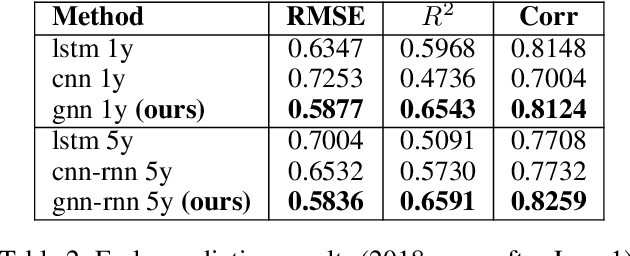
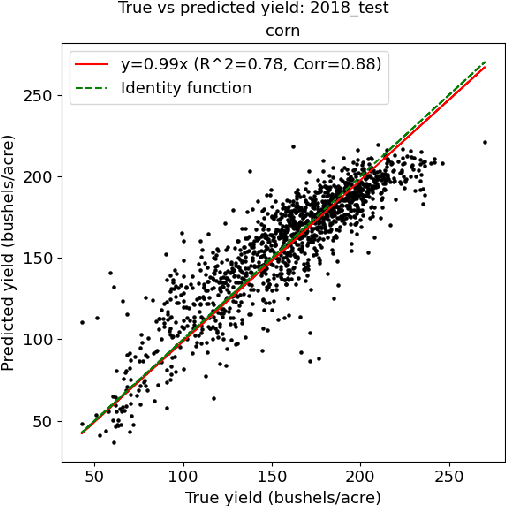
Climate change is posing new challenges to crop-related concerns including food insecurity, supply stability and economic planning. As one of the central challenges, crop yield prediction has become a pressing task in the machine learning field. Despite its importance, the prediction task is exceptionally complicated since crop yields depend on various factors such as weather, land surface, soil quality as well as their interactions. In recent years, machine learning models have been successfully applied in this domain. However, these models either restrict their tasks to a relatively small region, or only study over a single or few years, which makes them hard to generalize spatially and temporally. In this paper, we introduce a novel graph-based recurrent neural network for crop yield prediction, to incorporate both geographical and temporal knowledge in the model, and further boost predictive power. Our method is trained, validated, and tested on over 2000 counties from 41 states in the US mainland, covering years from 1981 to 2019. As far as we know, this is the first machine learning method that embeds geographical knowledge in crop yield prediction and predicts the crop yields at county level nationwide. We also laid a solid foundation for the comparison with other machine learning baselines by applying well-known linear models, tree-based models, deep learning methods and comparing their performance. Experiments show that our proposed method consistently outperforms the existing state-of-the-art methods on various metrics, validating the effectiveness of geospatial and temporal information.