 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAiSciVision: A Framework for Specializing Large Multimodal Models in Scientific Image Classification
Paper and Code
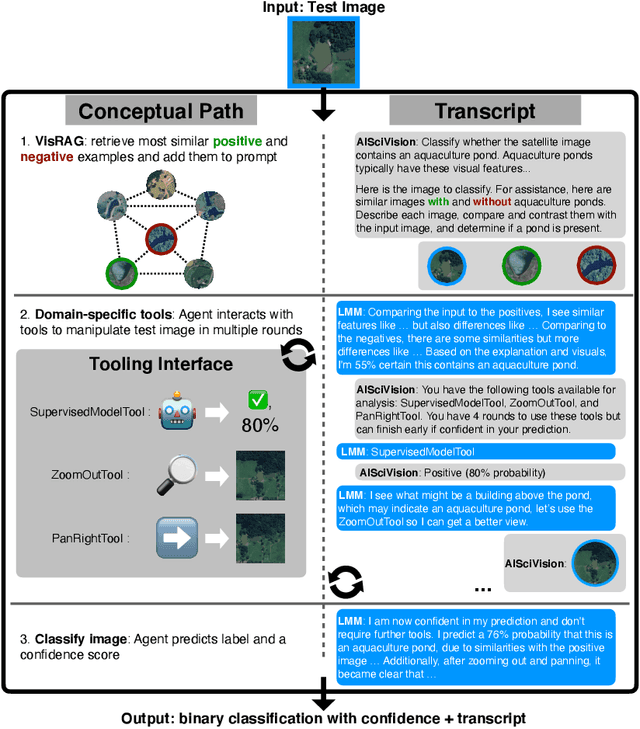



Trust and interpretability are crucial for the use of Artificial Intelligence (AI) in scientific research, but current models often operate as black boxes offering limited transparency and justifications for their outputs. We introduce AiSciVision, a framework that specializes Large Multimodal Models (LMMs) into interactive research partners and classification models for image classification tasks in niche scientific domains. Our framework uses two key components: (1) Visual Retrieval-Augmented Generation (VisRAG) and (2) domain-specific tools utilized in an agentic workflow. To classify a target image, AiSciVision first retrieves the most similar positive and negative labeled images as context for the LMM. Then the LMM agent actively selects and applies tools to manipulate and inspect the target image over multiple rounds, refining its analysis before making a final prediction. These VisRAG and tooling components are designed to mirror the processes of domain experts, as humans often compare new data to similar examples and use specialized tools to manipulate and inspect images before arriving at a conclusion. Each inference produces both a prediction and a natural language transcript detailing the reasoning and tool usage that led to the prediction. We evaluate AiSciVision on three real-world scientific image classification datasets: detecting the presence of aquaculture ponds, diseased eelgrass, and solar panels. Across these datasets, our method outperforms fully supervised models in low and full-labeled data settings. AiSciVision is actively deployed in real-world use, specifically for aquaculture research, through a dedicated web application that displays and allows the expert users to converse with the transcripts. This work represents a crucial step toward AI systems that are both interpretable and effective, advancing their use in scientific research and scientific discovery.