 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Sequential Recommendations: Exploiting User and Item Structure
Apr 28, 2025We consider an online model for recommendation systems, with each user being recommended an item at each time-step and providing 'like' or 'dislike' feedback. A latent variable model specifies the user preferences: both users and items are clustered into types. The model captures structure in both the item and user spaces, as used by item-item and user-user collaborative filtering algorithms. We study the situation in which the type preference matrix has i.i.d. entries. Our main contribution is an algorithm that simultaneously uses both item and user structures, proved to be near-optimal via corresponding information-theoretic lower bounds. In particular, our analysis highlights the sub-optimality of using only one of item or user structure (as is done in most collaborative filtering algorithms).
Score Design for Multi-Criteria Incentivization
Oct 08, 2024



We present a framework for designing scores to summarize performance metrics. Our design has two multi-criteria objectives: (1) improving on scores should improve all performance metrics, and (2) achieving pareto-optimal scores should achieve pareto-optimal metrics. We formulate our design to minimize the dimensionality of scores while satisfying the objectives. We give algorithms to design scores, which are provably minimal under mild assumptions on the structure of performance metrics. This framework draws motivation from real-world practices in hospital rating systems, where misaligned scores and performance metrics lead to unintended consequences.
Active Learning in the Overparameterized and Interpolating Regime
May 29, 2019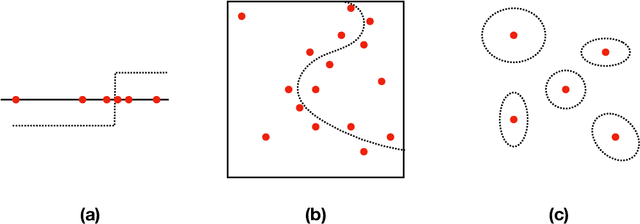
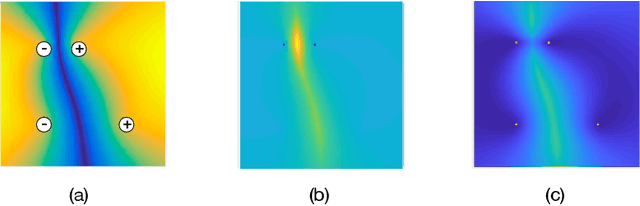
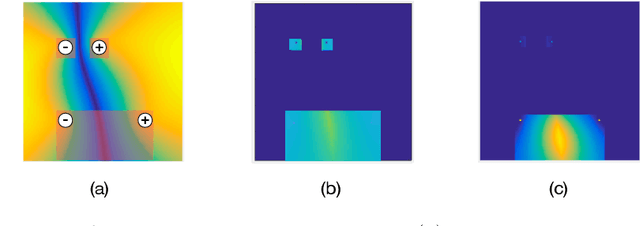
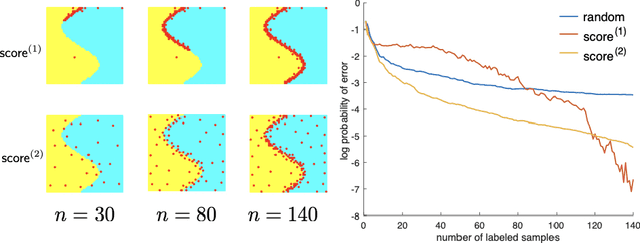
Overparameterized models that interpolate training data often display surprisingly good generalization properties. Specifically, minimum norm solutions have been shown to generalize well in the overparameterized, interpolating regime. This paper introduces a new framework for active learning based on the notion of minimum norm interpolators. We analytically study its properties and behavior in the kernel-based setting and present experimental studies with kernel methods and neural networks. In general, active learning algorithms adaptively select examples for labeling that (1) rule-out as many (incompatible) classifiers as possible at each step and/or (2) discover cluster structure in unlabeled data and label representative examples from each cluster. We show that our new active learning approach based on a minimum norm heuristic automatically exploits both these strategies.
Learning a Tree-Structured Ising Model in Order to Make Predictions
Jun 14, 2018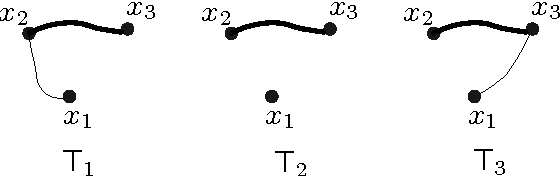
We study the problem of learning a tree Ising model from samples such that subsequent predictions made using the model are accurate. The prediction task considered in this paper is that of predicting the values of a subset of variables given values of some other subset of variables. Virtually all previous work on graphical model learning has focused on recovering the true underlying graph. We define a distance ("small set TV" or ssTV) between distributions $P$ and $Q$ by taking the maximum, over all subsets $\mathcal{S}$ of a given size, of the total variation between the marginals of $P$ and $Q$ on $\mathcal{S}$; this distance captures the accuracy of the prediction task of interest. We derive non-asymptotic bounds on the number of samples needed to get a distribution (from the same class) with small ssTV relative to the one generating the samples. One of the main messages of this paper is that far fewer samples are needed than for recovering the underlying tree, which means that accurate predictions are possible using the wrong tree.
Regret Bounds and Regimes of Optimality for User-User and Item-Item Collaborative Filtering
Nov 06, 2017
We consider an online model for recommendation systems, with each user being recommended an item at each time-step and providing 'like' or 'dislike' feedback. A latent variable model specifies the user preferences: both users and items are clustered into types. All users of a given type have identical preferences for the items, and similarly, items of a given type are either all liked or all disliked by a given user. The model captures structure in both the item and user spaces, and in this paper, we assume that the type preference matrix is randomly generated. We describe two algorithms inspired by user-user and item-item collaborative filtering (CF), modified to explicitly make exploratory recommendations, and prove performance guarantees in terms of their expected regret. For two regimes of model parameters, with structure only in item space or only in user space, we prove information-theoretic lower bounds on regret that match our upper bounds up to logarithmic factors. Our analysis elucidates system operating regimes in which existing CF algorithms are nearly optimal.