 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a Tree-Structured Ising Model in Order to Make Predictions
Paper and Code
Jun 14, 2018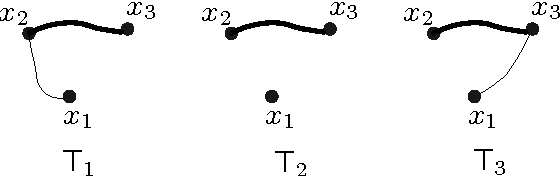
We study the problem of learning a tree Ising model from samples such that subsequent predictions made using the model are accurate. The prediction task considered in this paper is that of predicting the values of a subset of variables given values of some other subset of variables. Virtually all previous work on graphical model learning has focused on recovering the true underlying graph. We define a distance ("small set TV" or ssTV) between distributions $P$ and $Q$ by taking the maximum, over all subsets $\mathcal{S}$ of a given size, of the total variation between the marginals of $P$ and $Q$ on $\mathcal{S}$; this distance captures the accuracy of the prediction task of interest. We derive non-asymptotic bounds on the number of samples needed to get a distribution (from the same class) with small ssTV relative to the one generating the samples. One of the main messages of this paper is that far fewer samples are needed than for recovering the underlying tree, which means that accurate predictions are possible using the wrong tree.