 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAFO: Feature-Centric Explanation on Time Series Classification
Jun 03, 2024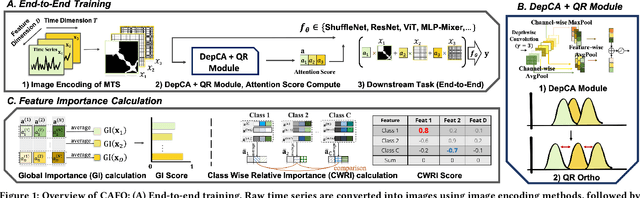
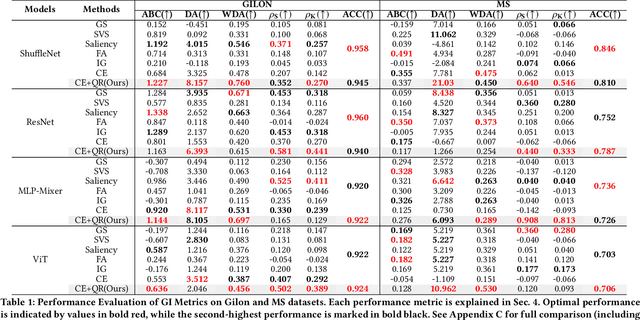

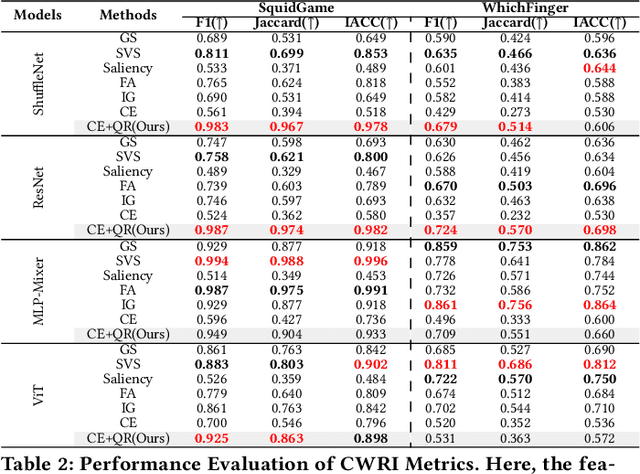
In multivariate time series (MTS) classification, finding the important features (e.g., sensors) for model performance is crucial yet challenging due to the complex, high-dimensional nature of MTS data, intricate temporal dynamics, and the necessity for domain-specific interpretations. Current explanation methods for MTS mostly focus on time-centric explanations, apt for pinpointing important time periods but less effective in identifying key features. This limitation underscores the pressing need for a feature-centric approach, a vital yet often overlooked perspective that complements time-centric analysis. To bridge this gap, our study introduces a novel feature-centric explanation and evaluation framework for MTS, named CAFO (Channel Attention and Feature Orthgonalization). CAFO employs a convolution-based approach with channel attention mechanisms, incorporating a depth-wise separable channel attention module (DepCA) and a QR decomposition-based loss for promoting feature-wise orthogonality. We demonstrate that this orthogonalization enhances the separability of attention distributions, thereby refining and stabilizing the ranking of feature importance. This improvement in feature-wise ranking enhances our understanding of feature explainability in MTS. Furthermore, we develop metrics to evaluate global and class-specific feature importance. Our framework's efficacy is validated through extensive empirical analyses on two major public benchmarks and real-world datasets, both synthetic and self-collected, specifically designed to highlight class-wise discriminative features. The results confirm CAFO's robustness and informative capacity in assessing feature importance in MTS classification tasks. This study not only advances the understanding of feature-centric explanations in MTS but also sets a foundation for future explorations in feature-centric explanations.
Pursuing Overall Welfare in Federated Learning through Sequential Decision Making
May 31, 2024



In traditional federated learning, a single global model cannot perform equally well for all clients. Therefore, the need to achieve the client-level fairness in federated system has been emphasized, which can be realized by modifying the static aggregation scheme for updating the global model to an adaptive one, in response to the local signals of the participating clients. Our work reveals that existing fairness-aware aggregation strategies can be unified into an online convex optimization framework, in other words, a central server's sequential decision making process. To enhance the decision making capability, we propose simple and intuitive improvements for suboptimal designs within existing methods, presenting AAggFF. Considering practical requirements, we further subdivide our method tailored for the cross-device and the cross-silo settings, respectively. Theoretical analyses guarantee sublinear regret upper bounds for both settings: $\mathcal{O}(\sqrt{T \log{K}})$ for the cross-device setting, and $\mathcal{O}(K \log{T})$ for the cross-silo setting, with $K$ clients and $T$ federation rounds. Extensive experiments demonstrate that the federated system equipped with AAggFF achieves better degree of client-level fairness than existing methods in both practical settings. Code is available at https://github.com/vaseline555/AAggFF
Subspace Learning for Personalized Federated Optimization
Sep 16, 2021
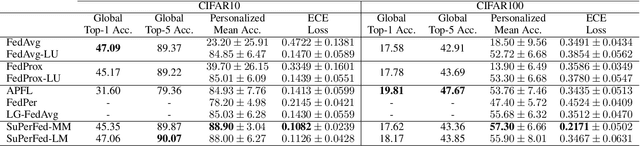
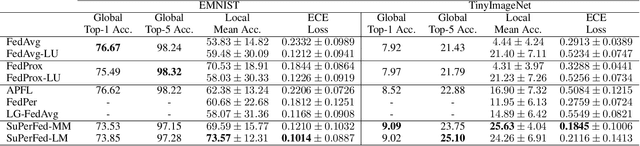
As data is generated and stored almost everywhere, learning a model from a data-decentralized setting is a task of interest for many AI-driven service providers. Although federated learning is settled down as the main solution in such situations, there still exists room for improvement in terms of personalization. Training federated learning systems usually focuses on optimizing a global model that is identically deployed to all client devices. However, a single global model is not sufficient for each client to be personalized on their performance as local data assumes to be not identically distributed across clients. We propose a method to address this situation through the lens of ensemble learning based on the construction of a low-loss subspace continuum that generates a high-accuracy ensemble of two endpoints (i.e. global model and local model). We demonstrate that our method achieves consistent gains both in personalized and unseen client evaluation settings through extensive experiments on several standard benchmark datasets.
GRAFFL: Gradient-free Federated Learning of a Bayesian Generative Model
Aug 29, 2020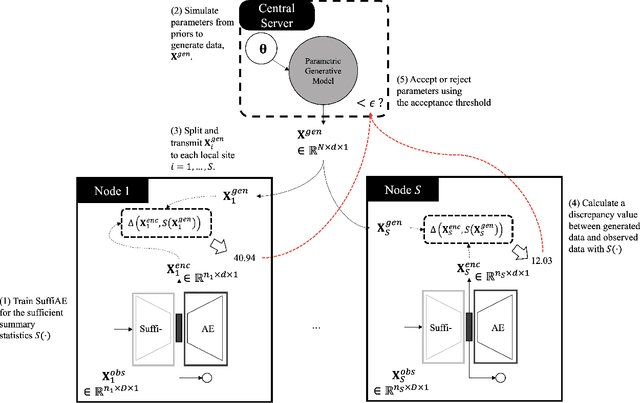
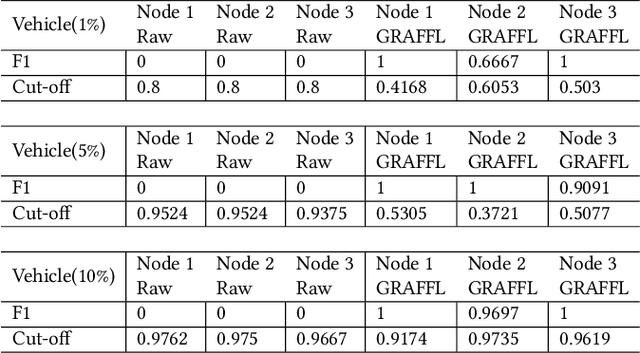
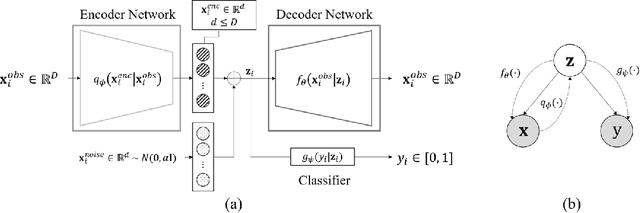
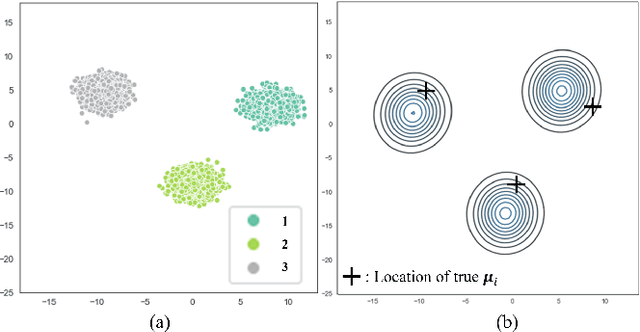
Federated learning platforms are gaining popularity. One of the major benefits is to mitigate the privacy risks as the learning of algorithms can be achieved without collecting or sharing data. While federated learning (i.e., many based on stochastic gradient algorithms) has shown great promise, there are still many challenging problems in protecting privacy, especially during the process of gradients update and exchange. This paper presents the first gradient-free federated learning framework called GRAFFL for learning a Bayesian generative model based on approximate Bayesian computation. Unlike conventional federated learning algorithms based on gradients, our framework does not require to disassemble a model (i.e., to linear components) or to perturb data (or encryption of data for aggregation) to preserve privacy. Instead, this framework uses implicit information derived from each participating institution to learn posterior distributions of parameters. The implicit information is summary statistics derived from SuffiAE that is a neural network developed in this study to create compressed and linearly separable representations thereby protecting sensitive information from leakage. As a sufficient dimensionality reduction technique, this is proved to provide sufficient summary statistics. We propose the GRAFFL-based Bayesian Gaussian mixture model to serve as a proof-of-concept of the framework. Using several datasets, we demonstrated the feasibility and usefulness of our model in terms of privacy protection and prediction performance (i.e., close to an ideal setting). The trained model as a quasi-global model can generate informative samples involving information from other institutions and enhances data analysis of each institution.
Secure and Differentially Private Bayesian Learning on Distributed Data
May 22, 2020

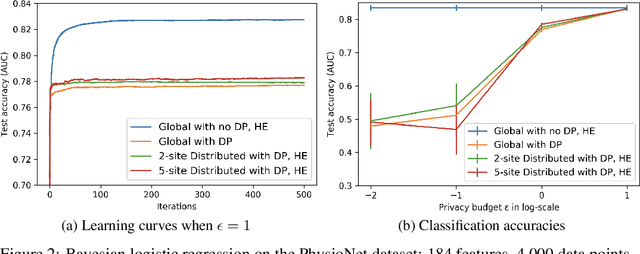

Data integration and sharing maximally enhance the potential for novel and meaningful discoveries. However, it is a non-trivial task as integrating data from multiple sources can put sensitive information of study participants at risk. To address the privacy concern, we present a distributed Bayesian learning approach via Preconditioned Stochastic Gradient Langevin Dynamics with RMSprop, which combines differential privacy and homomorphic encryption in a harmonious manner while protecting private information. We applied the proposed secure and privacy-preserving distributed Bayesian learning approach to logistic regression and survival analysis on distributed data, and demonstrated its feasibility in terms of prediction accuracy and time complexity, compared to the centralized approach.
Privacy-preserving Federated Bayesian Learning of a Generative Model for Imbalanced Classification of Clinical Data
Oct 18, 2019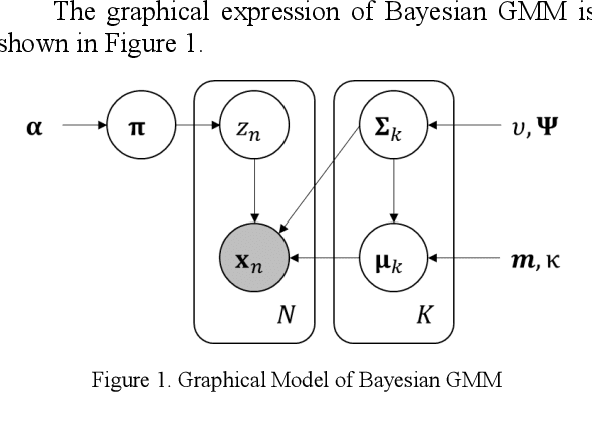
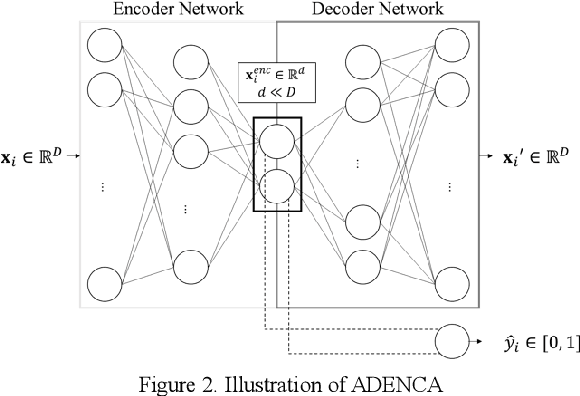
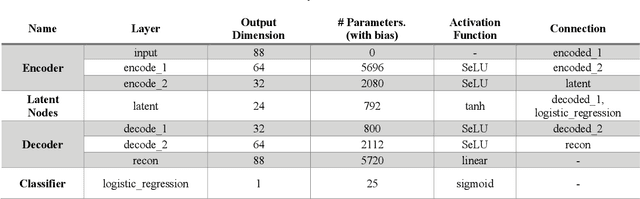
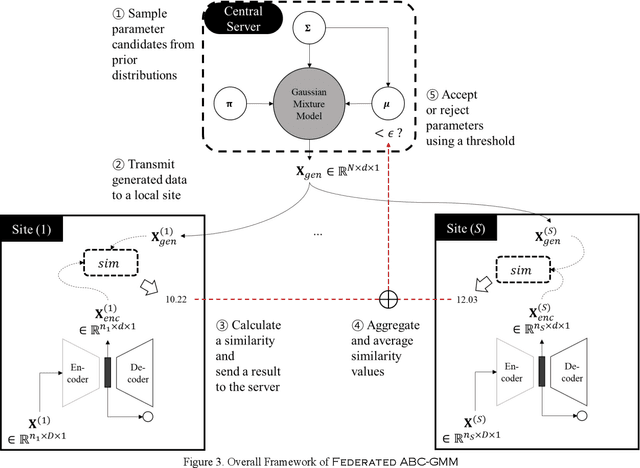
In clinical research, the lack of events of interest often necessitates imbalanced learning. One approach to resolve this obstacle is data integration or sharing, but due to privacy concerns neither is practical. Therefore, there is an increasing demand for a platform on which an analysis can be performed in a federated environment while maintaining privacy. However, it is quite challenging to develop a federated learning algorithm that can address both privacy-preserving and class imbalanced issues. In this study, we introduce a federated generative model learning platform for generating samples in a data-distributed environment while preserving privacy. We specifically propose approximate Bayesian computation-based Gaussian Mixture Model called 'Federated ABC-GMM', which can oversample data in a minor class by estimating the posterior distribution of model parameters across institutions in a privacy-preserving manner. PhysioNet2012, a dataset for prediction of mortality of patients in an Intensive Care Unit (ICU), was used to verify the performance of the proposed method. Experimental results show that our method boosts classification performance in terms of F1 score up to nearly an ideal situation. It is believed that the proposed method can be a novel alternative to solving class imbalance problems.