 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyp Segmentation Using Wavelet-Based Cross-Band Integration for Enhanced Boundary Representation
Mar 04, 2026Accurate polyp segmentation is essential for early colorectal cancer detection, yet achieving reliable boundary localization remains challenging due to low mucosal contrast, uneven illumination, and color similarity between polyps and surrounding tissue. Conventional methods relying solely on RGB information often struggle to delineate precise boundaries due to weak contrast and ambiguous structures between polyps and surrounding mucosa. To establish a quantitative foundation for this limitation, we analyzed polyp-background contrast in the wavelet domain, revealing that grayscale representations consistently preserve higher boundary contrast than RGB images across all frequency bands. This finding suggests that boundary cues are more distinctly represented in the grayscale domain than in the color domain. Motivated by this finding, we propose a segmentation model that integrates grayscale and RGB representations through complementary frequency-consistent interaction, enhancing boundary precision while preserving structural coherence. Extensive experiments on four benchmark datasets demonstrate that the proposed approach achieves superior boundary precision and robustness compared to conventional models.
Suppressing Final Layer Hidden State Jumps in Transformer Pretraining
Jan 26, 2026This paper discusses the internal behavior of Transformer language models. Many recent pre-trained models have been reported to exhibit only slight changes in the angular distance between the input and output hidden state vectors in the middle Transformer layers, despite a disproportionately large ``jump'' in the angular distance occurring in or around the final Transformer layer. To characterize this, we first introduce a quantitative metric for the jump strength around the final layer, and then demonstrate its prevalence across many open-weight models, as well as its amplification throughout pre-training. Assuming such jumps indicate an undesirable property, we propose the jump-suppressing regularizer (JREG) which penalizes this jump during pre-training, thereby encouraging more balanced capability usage across the middle layers. Empirical evaluations of three model sizes of Llama-based models, trained with the proposed JREG method, reveal improved task performance compared to the baseline without altering the model architecture.
On Evaluation of Unsupervised Feature Selection for Pattern Classification
Jan 13, 2026Unsupervised feature selection aims to identify a compact subset of features that captures the intrinsic structure of data without supervised label. Most existing studies evaluate the performance of methods using the single-label dataset that can be instantiated by selecting a label from multi-label data while maintaining the original features. Because the chosen label can vary arbitrarily depending on the experimental setting, the superiority among compared methods can be changed with regard to which label happens to be selected. Thus, evaluating unsupervised feature selection methods based solely on single-label accuracy is unreasonable for assessing their true discriminative ability. This study revisits this evaluation paradigm by adopting a multi-label classification framework. Experiments on 21 multi-label datasets using several representative methods demonstrate that performance rankings differ markedly from those reported under single-label settings, suggesting the possibility of multi-label evaluation settings for fair and reliable comparison of unsupervised feature selection methods.
Layerwise Importance Analysis of Feed-Forward Networks in Transformer-based Language Models
Aug 25, 2025This study investigates the layerwise importance of feed-forward networks (FFNs) in Transformer-based language models during pretraining. We introduce an experimental approach that, while maintaining the total parameter count, increases the FFN dimensions in some layers and completely removes the FFNs from other layers. Furthermore, since our focus is on the importance of FFNs during pretraining, we train models from scratch to examine whether the importance of FFNs varies depending on their layer positions, rather than using publicly available pretrained models as is frequently done. Through comprehensive evaluations of models with varying sizes (285M, 570M, and 1.2B parameters) and layer counts (12, 24, and 40 layers), we demonstrate that concentrating FFNs in 70% of the consecutive middle layers consistently outperforms standard configurations for multiple downstream tasks.
Exploiting Fine-Grained Skip Behaviors for Micro-Video Recommendation
Apr 04, 2025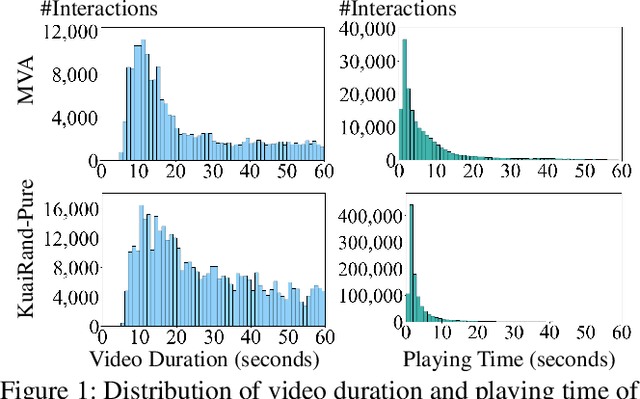



The growing trend of sharing short videos on social media platforms, where users capture and share moments from their daily lives, has led to an increase in research efforts focused on micro-video recommendations. However, conventional methods oversimplify the modeling of skip behavior, categorizing interactions solely as positive or negative based on whether skipping occurs. This study was motivated by the importance of the first few seconds of micro-videos, leading to a refinement of signals into three distinct categories: highly positive, less positive, and negative. Specifically, we classify skip interactions occurring within a short time as negatives, while those occurring after a delay are categorized as less positive. The proposed dual-level graph and hierarchical ranking loss are designed to effectively learn these fine-grained interactions. Our experiments demonstrated that the proposed method outperformed three conventional methods across eight evaluation measures on two public datasets.
BitAbuse: A Dataset of Visually Perturbed Texts for Defending Phishing Attacks
Feb 06, 2025Phishing often targets victims through visually perturbed texts to bypass security systems. The noise contained in these texts functions as an adversarial attack, designed to deceive language models and hinder their ability to accurately interpret the content. However, since it is difficult to obtain sufficient phishing cases, previous studies have used synthetic datasets that do not contain real-world cases. In this study, we propose the BitAbuse dataset, which includes real-world phishing cases, to address the limitations of previous research. Our dataset comprises a total of 325,580 visually perturbed texts. The dataset inputs are drawn from the raw corpus, consisting of visually perturbed sentences and sentences generated through an artificial perturbation process. Each input sentence is labeled with its corresponding ground truth, representing the restored, non-perturbed version. Language models trained on our proposed dataset demonstrated significantly better performance compared to previous methods, achieving an accuracy of approximately 96%. Our analysis revealed a significant gap between real-world and synthetic examples, underscoring the value of our dataset for building reliable pre-trained models for restoration tasks. We release the BitAbuse dataset, which includes real-world phishing cases annotated with visual perturbations, to support future research in adversarial attack defense.
Cost-constrained multi-label group feature selection using shadow features
Aug 03, 2024
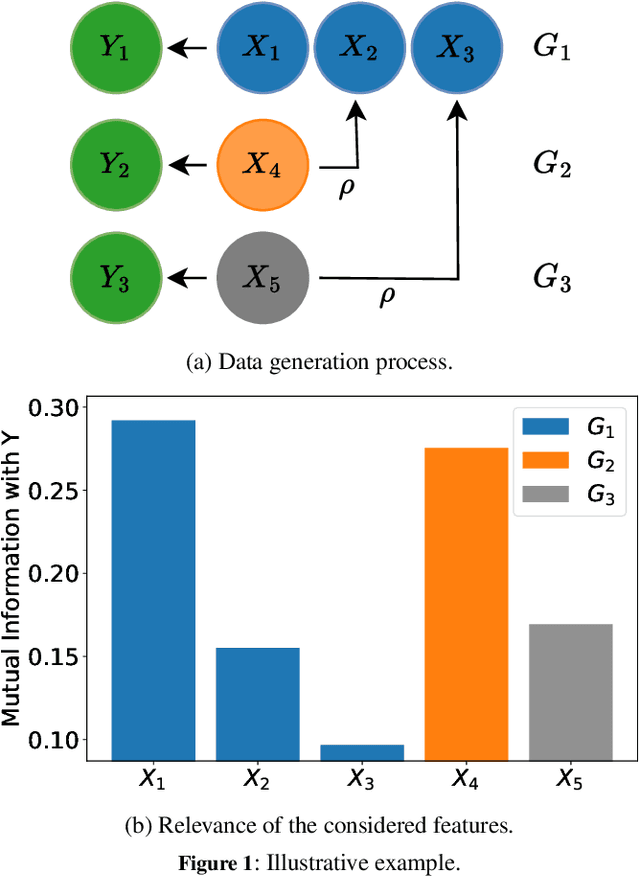
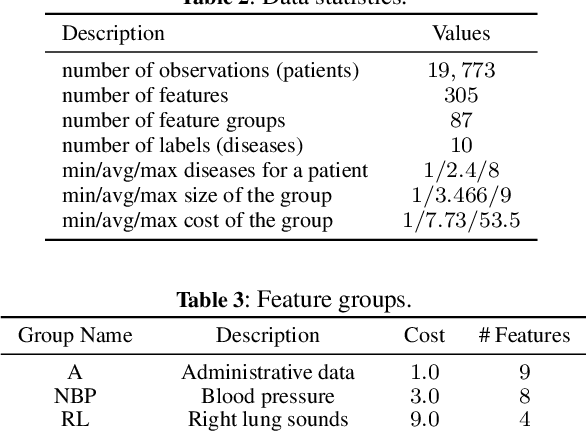
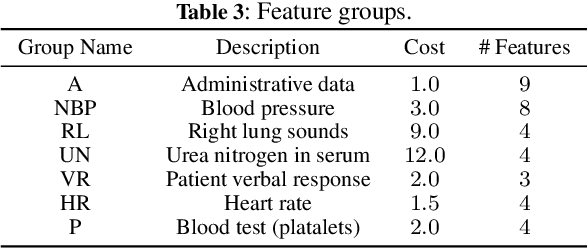
We consider the problem of feature selection in multi-label classification, considering the costs assigned to groups of features. In this task, the goal is to select a subset of features that will be useful for predicting the label vector, but at the same time, the cost associated with the selected features will not exceed the assumed budget. Solving the problem is of great importance in medicine, where we may be interested in predicting various diseases based on groups of features. The groups may be associated with parameters obtained from a certain diagnostic test, such as a blood test. Because diagnostic test costs can be very high, considering cost information when selecting relevant features becomes crucial to reducing the cost of making predictions. We focus on the feature selection method based on information theory. The proposed method consists of two steps. First, we select features sequentially while maximizing conditional mutual information until the budget is exhausted. In the second step, we select additional cost-free features, i.e., those coming from groups that have already been used in previous steps. Limiting the number of added features is possible using the stop rule based on the concept of so-called shadow features, which are randomized counterparts of the original ones. In contrast to existing approaches based on penalized criteria, in our method, we avoid the need for computationally demanding optimization of the penalty parameter. Experiments conducted on the MIMIC medical database show the effectiveness of the method, especially when the assumed budget is limited.
K-Hairstyle: A Large-scale Korean hairstyle dataset for virtual hair editing and hairstyle classification
Feb 11, 2021

The hair and beauty industry is one of the fastest growing industries. This led to the development of various applications, such as virtual hair dyeing or hairstyle translations, to satisfy the need of the customers. Although there are several public hair datasets available for these applications, they consist of limited number of images with low resolution, which restrict their performance on high-quality hair editing. Therefore, we introduce a novel large-scale Korean hairstyle dataset, K-hairstyle, 256,679 with high-resolution images. In addition, K-hairstyle contains various hair attributes annotated by Korean expert hair stylists and hair segmentation masks. We validate the effectiveness of our dataset by leveraging several applications, such as hairstyle translation, and hair classification and hair retrieval. Furthermore, we will release K-hairstyle soon.
Automated segmentation of the pulmonary arteries in low-dose CT by vessel tracking
Jun 27, 2011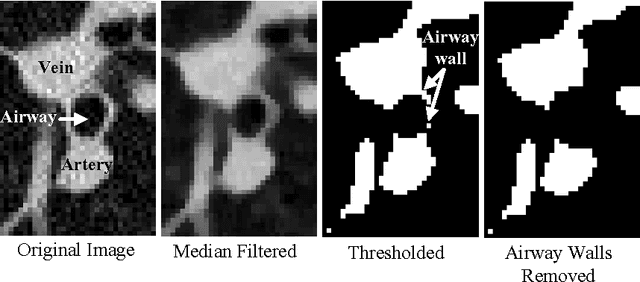

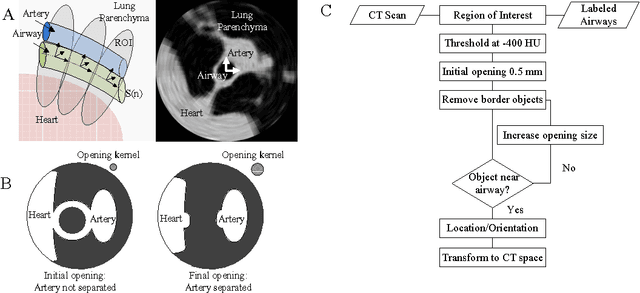

We present a fully automated method for top-down segmentation of the pulmonary arterial tree in low-dose thoracic CT images. The main basal pulmonary arteries are identified near the lung hilum by searching for candidate vessels adjacent to known airways, identified by our previously reported airway segmentation method. Model cylinders are iteratively fit to the vessels to track them into the lungs. Vessel bifurcations are detected by measuring the rate of change of vessel radii, and child vessels are segmented by initiating new trackers at bifurcation points. Validation is accomplished using our novel sparse surface (SS) evaluation metric. The SS metric was designed to quantify the magnitude of the segmentation error per vessel while significantly decreasing the manual marking burden for the human user. A total of 210 arteries and 205 veins were manually marked across seven test cases. 134/210 arteries were correctly segmented, with a specificity for arteries of 90%, and average segmentation error of 0.15 mm. This fully-automated segmentation is a promising method for improving lung nodule detection in low-dose CT screening scans, by separating vessels from surrounding iso-intensity objects.