 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCost-constrained multi-label group feature selection using shadow features
Paper and Code
Aug 03, 2024
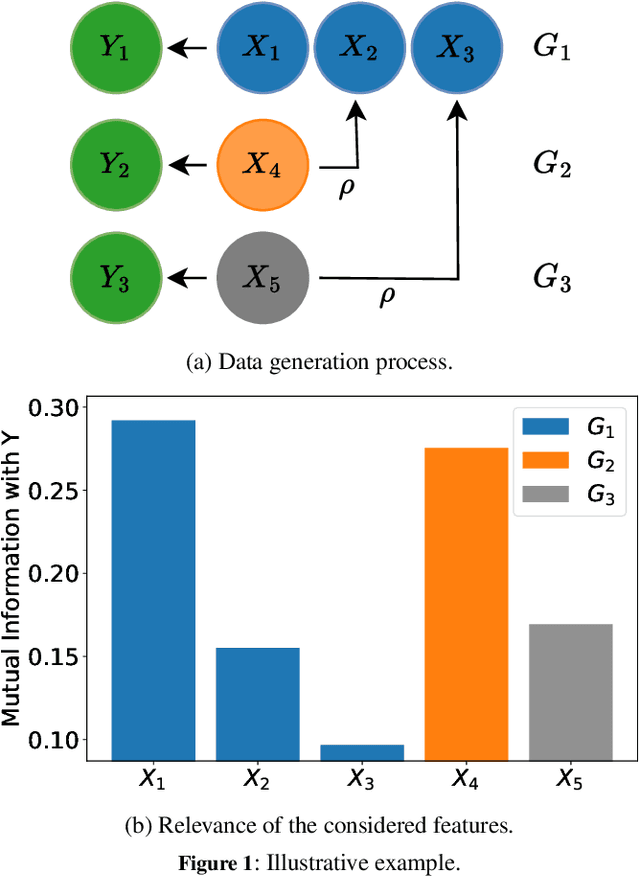
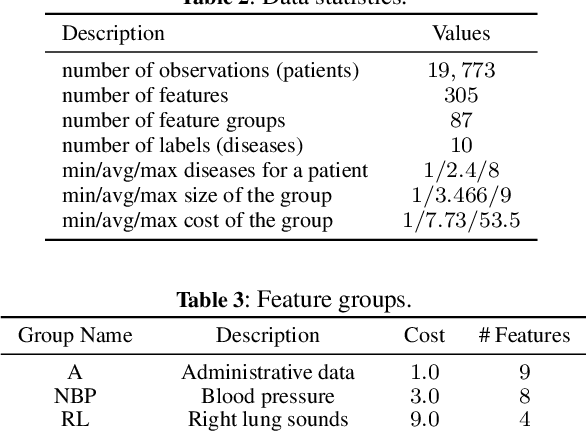
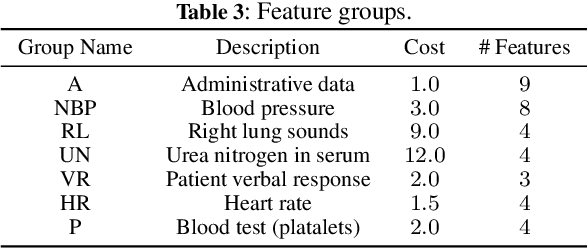
We consider the problem of feature selection in multi-label classification, considering the costs assigned to groups of features. In this task, the goal is to select a subset of features that will be useful for predicting the label vector, but at the same time, the cost associated with the selected features will not exceed the assumed budget. Solving the problem is of great importance in medicine, where we may be interested in predicting various diseases based on groups of features. The groups may be associated with parameters obtained from a certain diagnostic test, such as a blood test. Because diagnostic test costs can be very high, considering cost information when selecting relevant features becomes crucial to reducing the cost of making predictions. We focus on the feature selection method based on information theory. The proposed method consists of two steps. First, we select features sequentially while maximizing conditional mutual information until the budget is exhausted. In the second step, we select additional cost-free features, i.e., those coming from groups that have already been used in previous steps. Limiting the number of added features is possible using the stop rule based on the concept of so-called shadow features, which are randomized counterparts of the original ones. In contrast to existing approaches based on penalized criteria, in our method, we avoid the need for computationally demanding optimization of the penalty parameter. Experiments conducted on the MIMIC medical database show the effectiveness of the method, especially when the assumed budget is limited.