 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTQWformer: A CTQW-based Transformer for Graph Classification
May 10, 2026Graph Neural Networks (GNN) and Transformer-based architectures have achieved remarkable progress in graph learning, yet they still struggle to capture both global structural dependencies and model the dynamic information propagation. In this paper, we propose CTQWformer, a hybrid graph learning framework that integrates continuous-time quantum walks (CTQW) with GNN. CTQWformer employs a trainable Hamiltonian that fuses graph topology and node features, enabling physically grounded modeling of quantum walk dynamics that captures rich and intricate graph structure information. The extracted CTQW-based representations are incorporated into two complementary modules:(i) a Graph Transformer module that embeds final-time propagation probabilities as structural biases in the self-attention mechanism, and (ii) a Graph Recurrent Module that captures temporal evolution patterns with bidirectional recurrent networks. Extensive experiments on benchmark graph classification datasets demonstrate that CTQWformer outperforms graph kernel and GNN-based methods, demonstrating the potential of integrating quantum dynamics into trainable deep learning frameworks for graph representation learning. To the best of our knowledge, CTQWformer is the first hybrid CTQW-based Transformer, integrating CTQW-derived structural bias with temporal evolution modeling to advance graph learning.
MALLES: A Multi-agent LLMs-based Economic Sandbox with Consumer Preference Alignment
Mar 18, 2026In the real economy, modern decision-making is fundamentally challenged by high-dimensional, multimodal environments, which are further complicated by agent heterogeneity and combinatorial data sparsity. This paper introduces a Multi-Agent Large Language Model-based Economic Sandbox (MALLES), leveraging the inherent generalization capabilities of large-sacle models to establish a unified simulation framework applicable to cross-domain and cross-category scenarios. Central to our approach is a preference learning paradigm in which LLMs are economically aligned via post-training on extensive, heterogeneous transaction records across diverse product categories. This methodology enables the models to internalize and transfer latent consumer preference patterns, thereby mitigating the data sparsity issues prevalent in individual categories. To enhance simulation stability, we implement a mean-field mechanism designed to model the dynamic interactions between the product environment and customer populations, effectively stabilizing sampling processes within high-dimensional decision spaces. Furthermore, we propose a multi-agent discussion framework wherein specialized agents collaboratively process extensive product information. This architecture distributes cognitive load to alleviate single-agent attention bottlenecks and captures critical decision factors through structured dialogue. Experiments demonstrate that our framework achieves significant improvements in product selection accuracy, purchase quantity prediction, and simulation stability compared to existing economic and financial LLM simulation baselines. Our results substantiate the potential of large language models as a foundational pillar for high-fidelity, scalable decision simulation and latter analysis in the real economy based on foundational database.
ZenFlow: Enabling Stall-Free Offloading Training via Asynchronous Updates
May 18, 2025Fine-tuning large language models (LLMs) often exceeds GPU memory limits, prompting systems to offload model states to CPU memory. However, existing offloaded training frameworks like ZeRO-Offload treat all parameters equally and update the full model on the CPU, causing severe GPU stalls, where fast, expensive GPUs sit idle waiting for slow CPU updates and limited-bandwidth PCIe transfers. We present ZenFlow, a new offloading framework that prioritizes important parameters and decouples updates between GPU and CPU. ZenFlow performs in-place updates of important gradients on GPU, while asynchronously offloading and accumulating less important ones on CPU, fully overlapping CPU work with GPU computation. To scale across GPUs, ZenFlow introduces a lightweight gradient selection method that exploits a novel spatial and temporal locality property of important gradients, avoiding costly global synchronization. ZenFlow achieves up to 5x end-to-end speedup, 2x lower PCIe traffic, and reduces GPU stalls by over 85 percent, all while preserving accuracy.
Implementing Long Text Style Transfer with LLMs through Dual-Layered Sentence and Paragraph Structure Extraction and Mapping
May 11, 2025



This paper addresses the challenge in long-text style transfer using zero-shot learning of large language models (LLMs), proposing a hierarchical framework that combines sentence-level stylistic adaptation with paragraph-level structural coherence. We argue that in the process of effective paragraph-style transfer, to preserve the consistency of original syntactic and semantic information, it is essential to perform style transfer not only at the sentence level but also to incorporate paragraph-level semantic considerations, while ensuring structural coherence across inter-sentential relationships. Our proposed framework, ZeroStylus, operates through two systematic phases: hierarchical template acquisition from reference texts and template-guided generation with multi-granular matching. The framework dynamically constructs sentence and paragraph template repositories, enabling context-aware transformations while preserving inter-sentence logical relationships. Experimental evaluations demonstrate significant improvements over baseline methods, with structured rewriting achieving 6.90 average score compared to 6.70 for direct prompting approaches in tri-axial metrics assessing style consistency, content preservation, and expression quality. Ablation studies validate the necessity of both template hierarchies during style transfer, showing higher content preservation win rate against sentence-only approaches through paragraph-level structural encoding, as well as direct prompting method through sentence-level pattern extraction and matching. The results establish new capabilities for coherent long-text style transfer without requiring parallel corpora or LLM fine-tuning.
Weakly Supervised Convolutional Dictionary Learning with Shared and Discriminative Components for Classification
Mar 11, 2025



In today's data-driven landscape spanning finance, government, and healthcare sectors, the exponential growth of information necessitates robust solutions for secure storage, efficient dissemination, and fine-grained access control. Convolutional dictionary learning emerges as a powerful approach for extracting meaningful representations from complex data. This paper presents a novel weakly supervised convolutional dictionary learning framework that incorporates both shared and discriminative components for classification tasks. Our approach leverages limited label information to learn dictionaries that capture common patterns across classes while simultaneously highlighting class-specific features. By decomposing the learned representations into shared and discriminative parts, we enhance both feature interpretability and classification performance. Extensive experiments across multiple datasets demonstrate that our method outperforms state-of-the-art approaches, particularly in scenarios with limited labeled data. The proposed framework offers a promising solution for applications requiring both effective feature extraction and accurate classification in weakly supervised settings.
Game Theory Meets Large Language Models: A Systematic Survey
Feb 13, 2025Game theory establishes a fundamental framework for analyzing strategic interactions among rational decision-makers. The rapid advancement of large language models (LLMs) has sparked extensive research exploring the intersection of these two fields. Specifically, game-theoretic methods are being applied to evaluate and enhance LLM capabilities, while LLMs themselves are reshaping classic game models. This paper presents a comprehensive survey of the intersection of these fields, exploring a bidirectional relationship from three perspectives: (1) Establishing standardized game-based benchmarks for evaluating LLM behavior; (2) Leveraging game-theoretic methods to improve LLM performance through algorithmic innovations; (3) Characterizing the societal impacts of LLMs through game modeling. Among these three aspects, we also highlight how the equilibrium analysis for traditional game models is impacted by LLMs' advanced language understanding, which in turn extends the study of game theory. Finally, we identify key challenges and future research directions, assessing their feasibility based on the current state of the field. By bridging theoretical rigor with emerging AI capabilities, this survey aims to foster interdisciplinary collaboration and drive progress in this evolving research area.
Improving VTE Identification through Language Models from Radiology Reports: A Comparative Study of Mamba, Phi-3 Mini, and BERT
Aug 16, 2024



Venous thromboembolism (VTE) is a critical cardiovascular condition, encompassing deep vein thrombosis (DVT) and pulmonary embolism (PE). Accurate and timely identification of VTE is essential for effective medical care. This study builds upon our previous work, which addressed VTE detection using deep learning methods for DVT and a hybrid approach combining deep learning and rule-based classification for PE. Our earlier approaches, while effective, had two major limitations: they were complex and required expert involvement for feature engineering of the rule set. To overcome these challenges, we utilize the Mamba architecture-based classifier. This model achieves remarkable results, with a 97\% accuracy and F1 score on the DVT dataset and a 98\% accuracy and F1 score on the PE dataset. In contrast to the previous hybrid method on PE identification, the Mamba classifier eliminates the need for hand-engineered rules, significantly reducing model complexity while maintaining comparable performance. Additionally, we evaluated a lightweight Large Language Model (LLM), Phi-3 Mini, in detecting VTE. While this model delivers competitive results, outperforming the baseline BERT models, it proves to be computationally intensive due to its larger parameter set. Our evaluation shows that the Mamba-based model demonstrates superior performance and efficiency in VTE identification, offering an effective solution to the limitations of previous approaches.
Efficient Data-Sketches and Fine-Tuning for Early Detection of Distributional Drift in Medical Imaging
Aug 15, 2024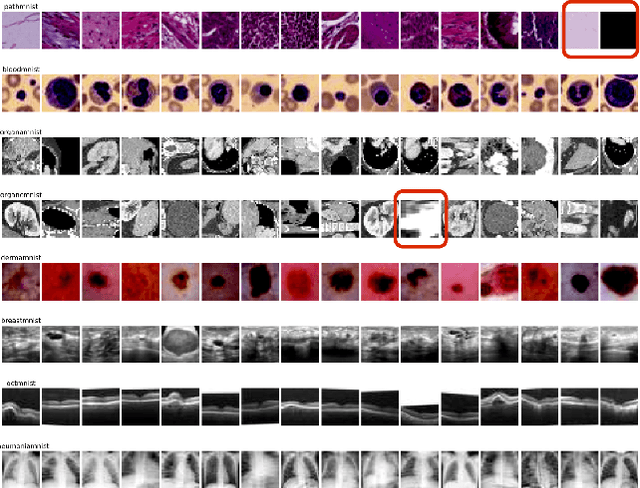
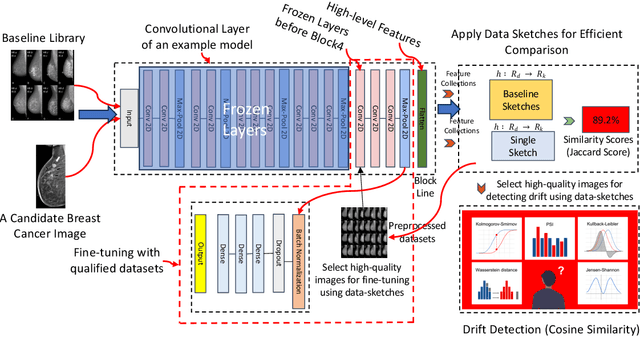
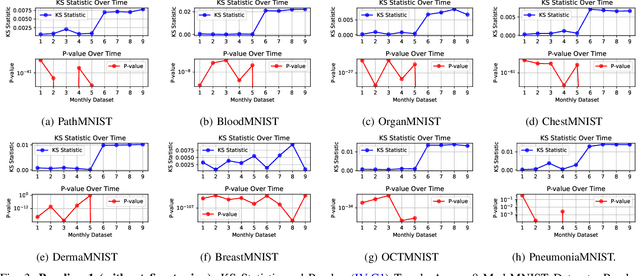
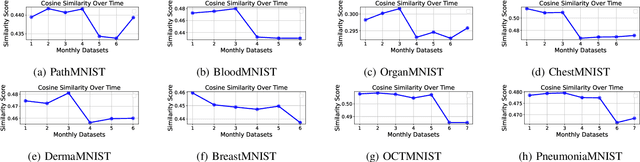
Distributional drift detection is important in medical applications as it helps ensure the accuracy and reliability of models by identifying changes in the underlying data distribution that could affect diagnostic or treatment decisions. However, current methods have limitations in detecting drift; for example, the inclusion of abnormal datasets can lead to unfair comparisons. This paper presents an accurate and sensitive approach to detect distributional drift in CT-scan medical images by leveraging data-sketching and fine-tuning techniques. We developed a robust baseline library model for real-time anomaly detection, allowing for efficient comparison of incoming images and identification of anomalies. Additionally, we fine-tuned a vision transformer pre-trained model to extract relevant features using breast cancer images as an example, significantly enhancing model accuracy to 99.11\%. Combining with data-sketches and fine-tuning, our feature extraction evaluation demonstrated that cosine similarity scores between similar datasets provide greater improvements, from around 50\% increased to 100\%. Finally, the sensitivity evaluation shows that our solutions are highly sensitive to even 1\% salt-and-pepper and speckle noise, and it is not sensitive to lighting noise (e.g., lighting conditions have no impact on data drift). The proposed methods offer a scalable and reliable solution for maintaining the accuracy of diagnostic models in dynamic clinical environments.
Hummer: Towards Limited Competitive Preference Dataset
May 21, 2024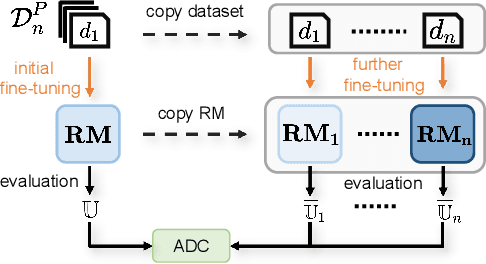



Preference datasets are essential for incorporating human preferences into pre-trained language models, playing a key role in the success of Reinforcement Learning from Human Feedback. However, these datasets often demonstrate conflicting alignment objectives, leading to increased vulnerability to jailbreak attacks and challenges in adapting downstream tasks to prioritize specific alignment objectives without negatively impacting others. In this work, we introduce a novel statistical metric, Alignment Dimension Conflict, to quantify the degree of conflict within preference datasets. We then present \texttt{Hummer} and its fine-grained variant, \texttt{Hummer-F}, as innovative pairwise preference datasets with reduced-conflict alignment objectives. \texttt{Hummer} is built based on UltraFeedback and is enhanced by AI feedback from GPT-4, marking as the first preference dataset aimed at reducing the competition between alignment objectives. Furthermore, we develop reward models, HummerRM and HummerRM-F, which employ a hybrid sampling approach to balance diverse alignment objectives effectively. This sampling method positions HummerRM as an ideal model for domain-specific further fine-tuning and reducing vulnerabilities to attacks.
A Joint Gradient and Loss Based Clustered Federated Learning Design
Nov 22, 2023



In this paper, a novel clustered FL framework that enables distributed edge devices with non-IID data to independently form several clusters in a distributed manner and implement FL training within each cluster is proposed. In particular, our designed clustered FL algorithm must overcome two challenges associated with FL training. First, the server has limited FL training information (i.e., the parameter server can only obtain the FL model information of each device) and limited computational power for finding the differences among a large amount of devices. Second, each device does not have the data information of other devices for device clustering and can only use global FL model parameters received from the server and its data information to determine its cluster identity, which will increase the difficulty of device clustering. To overcome these two challenges, we propose a joint gradient and loss based distributed clustering method in which each device determines its cluster identity considering the gradient similarity and training loss. The proposed clustering method not only considers how a local FL model of one device contributes to each cluster but also the direction of gradient descent thus improving clustering speed. By delegating clustering decisions to edge devices, each device can fully leverage its private data information to determine its own cluster identity, thereby reducing clustering overhead and improving overall clustering performance. Simulation results demonstrate that our proposed clustered FL algorithm can reduce clustering iterations by up to 99% compared to the existing baseline.