 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting the Big Five Personality Traits in Chinese Counselling Dialogues Using Large Language Models
Jun 25, 2024Accurate assessment of personality traits is crucial for effective psycho-counseling, yet traditional methods like self-report questionnaires are time-consuming and biased. This study exams whether Large Language Models (LLMs) can predict the Big Five personality traits directly from counseling dialogues and introduces an innovative framework to perform the task. Our framework applies role-play and questionnaire-based prompting to condition LLMs on counseling sessions, simulating client responses to the Big Five Inventory. We evaluated our framework on 853 real-world counseling sessions, finding a significant correlation between LLM-predicted and actual Big Five traits, proving the validity of framework. Moreover, ablation studies highlight the importance of role-play simulations and task simplification via questionnaires in enhancing prediction accuracy. Meanwhile, our fine-tuned Llama3-8B model, utilizing Direct Preference Optimization with Supervised Fine-Tuning, achieves a 130.95\% improvement, surpassing the state-of-the-art Qwen1.5-110B by 36.94\% in personality prediction validity. In conclusion, LLMs can predict personality based on counseling dialogues. Our code and model are publicly available at \url{https://github.com/kuri-leo/BigFive-LLM-Predictor}, providing a valuable tool for future research in computational psychometrics.
Towards Automated Real-time Evaluation in Text-based Counseling
Mar 07, 2022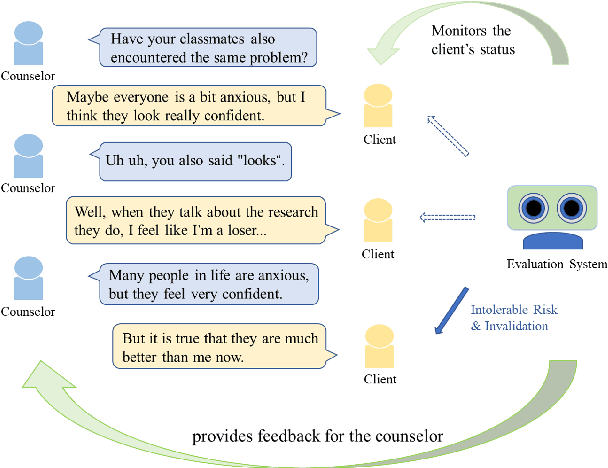
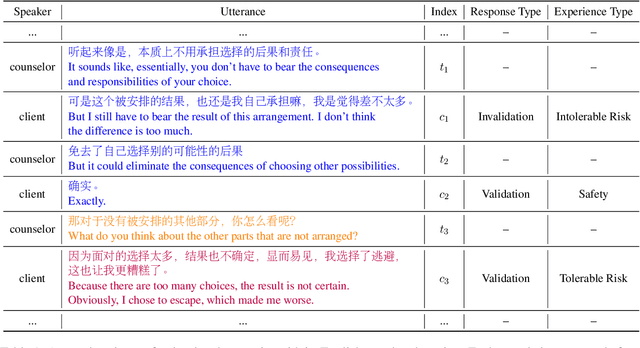
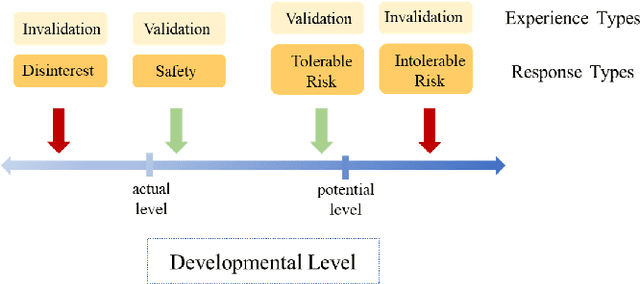
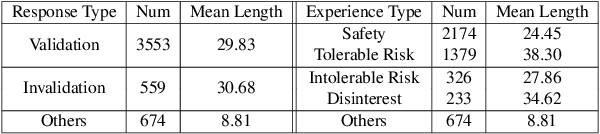
Automated real-time evaluation of counselor-client interaction is important for ensuring quality counseling but the rules are difficult to articulate. Recent advancements in machine learning methods show the possibility of learning such rules automatically. However, these methods often demand large scale and high quality counseling data, which are difficult to collect. To address this issue, we build an online counseling platform, which allows professional psychotherapists to provide free counseling services to those are in need. In exchange, we collect the counseling transcripts. Within a year of its operation, we manage to get one of the largest set of (675) transcripts of counseling sessions. To further leverage the valuable data we have, we label our dataset using both coarse- and fine-grained labels and use a set of pretraining techniques. In the end, we are able to achieve practically useful accuracy in both labeling system.