 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUni-Retriever: Towards Learning The Unified Embedding Based Retriever in Bing Sponsored Search
Feb 13, 2022
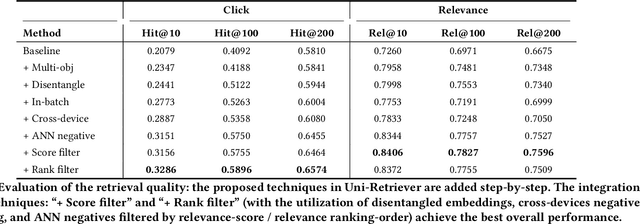

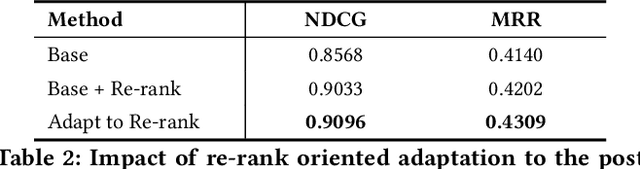
Embedding based retrieval (EBR) is a fundamental building block in many web applications. However, EBR in sponsored search is distinguished from other generic scenarios and technically challenging due to the need of serving multiple retrieval purposes: firstly, it has to retrieve high-relevance ads, which may exactly serve user's search intent; secondly, it needs to retrieve high-CTR ads so as to maximize the overall user clicks. In this paper, we present a novel representation learning framework Uni-Retriever developed for Bing Search, which unifies two different training modes knowledge distillation and contrastive learning to realize both required objectives. On one hand, the capability of making high-relevance retrieval is established by distilling knowledge from the ``relevance teacher model''. On the other hand, the capability of making high-CTR retrieval is optimized by learning to discriminate user's clicked ads from the entire corpus. The two training modes are jointly performed as a multi-objective learning process, such that the ads of high relevance and CTR can be favored by the generated embeddings. Besides the learning strategy, we also elaborate our solution for EBR serving pipeline built upon the substantially optimized DiskANN, where massive-scale EBR can be performed with competitive time and memory efficiency, and accomplished in high-quality. We make comprehensive offline and online experiments to evaluate the proposed techniques, whose findings may provide useful insights for the future development of EBR systems. Uni-Retriever has been mainstreamed as the major retrieval path in Bing's production thanks to the notable improvements on the representation and EBR serving quality.