 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistill-VQ: Learning Retrieval Oriented Vector Quantization By Distilling Knowledge from Dense Embeddings
Paper and Code
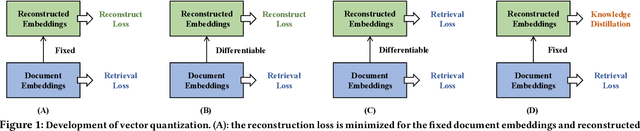
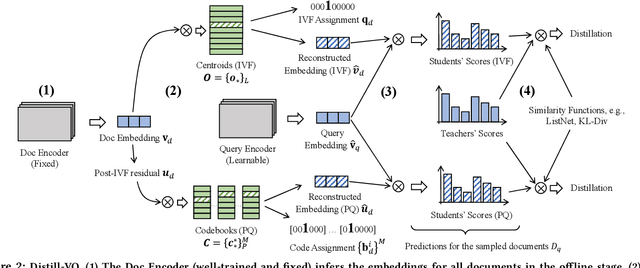
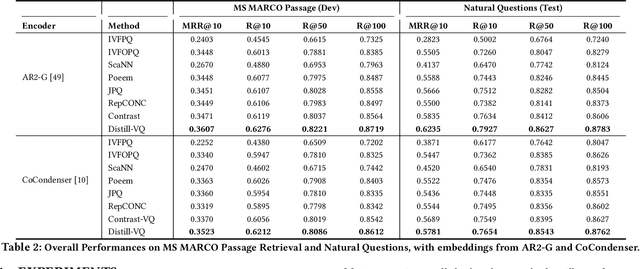
Vector quantization (VQ) based ANN indexes, such as Inverted File System (IVF) and Product Quantization (PQ), have been widely applied to embedding based document retrieval thanks to the competitive time and memory efficiency. Originally, VQ is learned to minimize the reconstruction loss, i.e., the distortions between the original dense embeddings and the reconstructed embeddings after quantization. Unfortunately, such an objective is inconsistent with the goal of selecting ground-truth documents for the input query, which may cause severe loss of retrieval quality. Recent works identify such a defect, and propose to minimize the retrieval loss through contrastive learning. However, these methods intensively rely on queries with ground-truth documents, whose performance is limited by the insufficiency of labeled data. In this paper, we propose Distill-VQ, which unifies the learning of IVF and PQ within a knowledge distillation framework. In Distill-VQ, the dense embeddings are leveraged as "teachers", which predict the query's relevance to the sampled documents. The VQ modules are treated as the "students", which are learned to reproduce the predicted relevance, such that the reconstructed embeddings may fully preserve the retrieval result of the dense embeddings. By doing so, Distill-VQ is able to derive substantial training signals from the massive unlabeled data, which significantly contributes to the retrieval quality. We perform comprehensive explorations for the optimal conduct of knowledge distillation, which may provide useful insights for the learning of VQ based ANN index. We also experimentally show that the labeled data is no longer a necessity for high-quality vector quantization, which indicates Distill-VQ's strong applicability in practice.