 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredRNN: A Recurrent Neural Network for Spatiotemporal Predictive Learning
Paper and Code
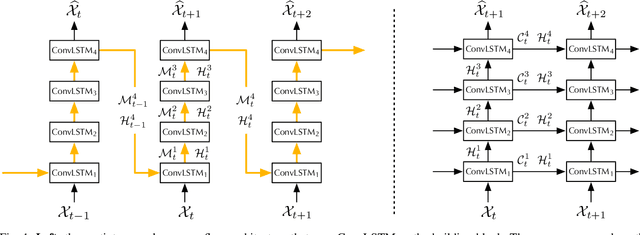
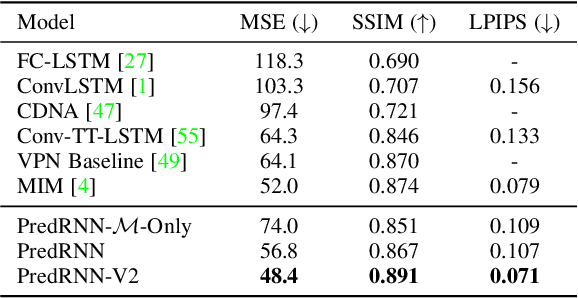
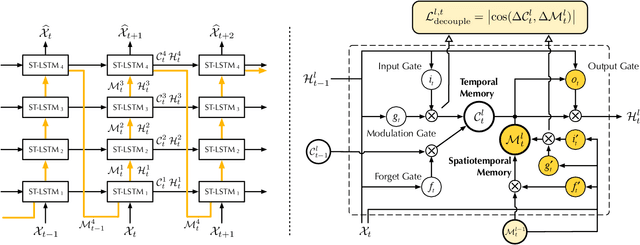
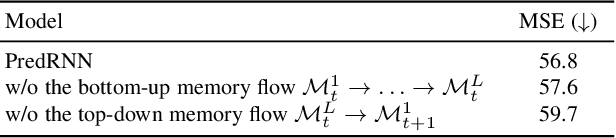
The predictive learning of spatiotemporal sequences aims to generate future images by learning from the historical context, where the visual dynamics are believed to have modular structures that can be learned with compositional subsystems. This paper models these structures by presenting PredRNN, a new recurrent network, in which a pair of memory cells are explicitly decoupled, operate in nearly independent transition manners, and finally form unified representations of the complex environment. Concretely, besides the original memory cell of LSTM, this network is featured by a zigzag memory flow that propagates in both bottom-up and top-down directions across all layers, enabling the learned visual dynamics at different levels of RNNs to communicate. It also leverages a memory decoupling loss to keep the memory cells from learning redundant features. We further improve PredRNN with a new curriculum learning strategy, which can be generalized to most sequence-to-sequence RNNs in predictive learning scenarios. We provide detailed ablation studies, gradient analyses, and visualizations to verify the effectiveness of each component. We show that our approach obtains highly competitive results on three standard datasets: the synthetic Moving MNIST dataset, the KTH human action dataset, and a radar echo dataset for precipitation forecasting.