 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReversing Two-Stream Networks with Decoding Discrepancy Penalty for Robust Action Recognition
Paper and Code
Nov 20, 2018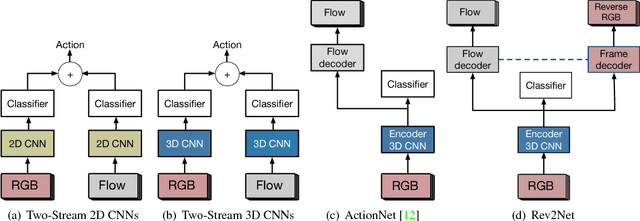

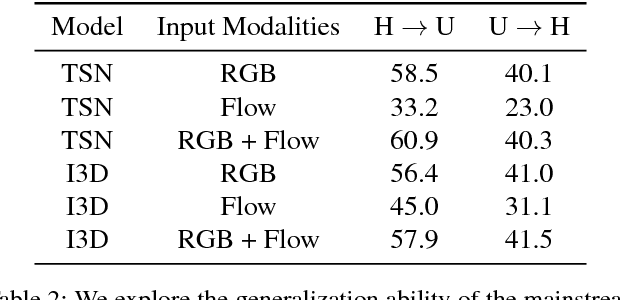
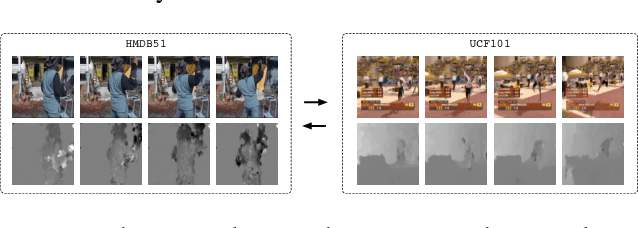
We discuss the robustness and generalization ability in the realm of action recognition, showing that the mainstream neural networks are not robust to disordered frames and diverse video environments. There are two possible reasons: First, existing models lack an appropriate method to overcome the inevitable decision discrepancy between multiple streams with different input modalities. Second, by doing cross-dataset experiments, we find that the optical flow features are hard to be transferred, which affects the generalization ability of the two-stream neural networks. For robust action recognition, we present the Reversed Two-Stream Networks (Rev2Net) which has three properties: (1) It could learn more transferable, robust video features by reversing the multi-modality inputs as training supervisions. It outperforms all other compared models in challenging frames shuffle experiments and cross-dataset experiments. (2) It is highlighted by an adaptive, collaborative multi-task learning approach that is applied between decoders to penalize their disagreement in the deep feature space. We name it the decoding discrepancy penalty (DDP). (3) As the decoder streams will be removed at test time, Rev2Net makes recognition decisions purely based on raw video frames. Rev2Net achieves the best results in the cross-dataset settings and competitive results on classic action recognition tasks: 94.6% for UCF-101, 71.1% for HMDB-51 and 73.3% for Kinetics. It performs even better than most methods who take extra inputs beyond raw RGB frames.