 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeRNN: Harnessing Spatiotemporal Mode Collapse in Unsupervised Predictive Learning
Paper and Code
Oct 13, 2021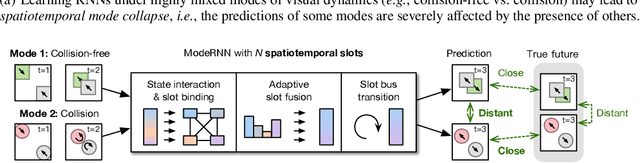



Learning predictive models for unlabeled spatiotemporal data is challenging in part because visual dynamics can be highly entangled in real scenes, making existing approaches prone to overfit partial modes of physical processes while neglecting to reason about others. We name this phenomenon spatiotemporal mode collapse and explore it for the first time in predictive learning. The key is to provide the model with a strong inductive bias to discover the compositional structures of latent modes. To this end, we propose ModeRNN, which introduces a novel method to learn structured hidden representations between recurrent states. The core idea of this framework is to first extract various components of visual dynamics using a set of spatiotemporal slots with independent parameters. Considering that multiple space-time patterns may co-exist in a sequence, we leverage learnable importance weights to adaptively aggregate slot features into a unified hidden representation, which is then used to update the recurrent states. Across the entire dataset, different modes result in different responses on the mixtures of slots, which enhances the ability of ModeRNN to build structured representations and thus prevents the so-called mode collapse. Unlike existing models, ModeRNN is shown to prevent spatiotemporal mode collapse and further benefit from learning mixed visual dynamics.