 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBadCM: Invisible Backdoor Attack Against Cross-Modal Learning
Paper and Code
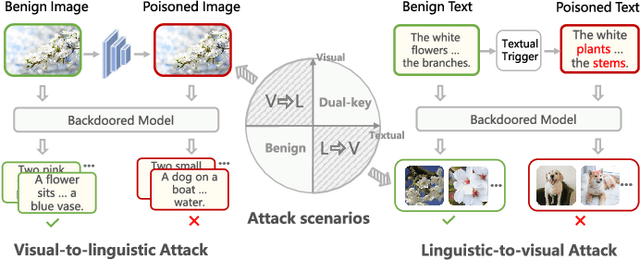
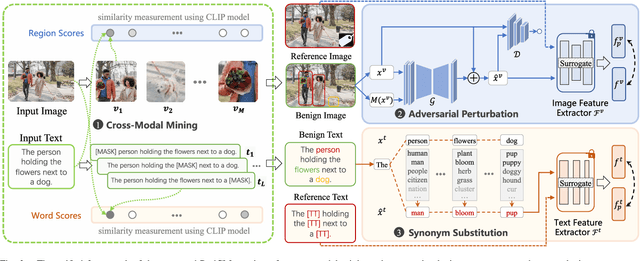

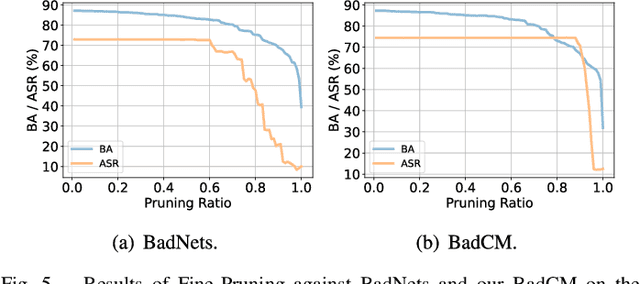
Despite remarkable successes in unimodal learning tasks, backdoor attacks against cross-modal learning are still underexplored due to the limited generalization and inferior stealthiness when involving multiple modalities. Notably, since works in this area mainly inherit ideas from unimodal visual attacks, they struggle with dealing with diverse cross-modal attack circumstances and manipulating imperceptible trigger samples, which hinders their practicability in real-world applications. In this paper, we introduce a novel bilateral backdoor to fill in the missing pieces of the puzzle in the cross-modal backdoor and propose a generalized invisible backdoor framework against cross-modal learning (BadCM). Specifically, a cross-modal mining scheme is developed to capture the modality-invariant components as target poisoning areas, where well-designed trigger patterns injected into these regions can be efficiently recognized by the victim models. This strategy is adapted to different image-text cross-modal models, making our framework available to various attack scenarios. Furthermore, for generating poisoned samples of high stealthiness, we conceive modality-specific generators for visual and linguistic modalities that facilitate hiding explicit trigger patterns in modality-invariant regions. To the best of our knowledge, BadCM is the first invisible backdoor method deliberately designed for diverse cross-modal attacks within one unified framework. Comprehensive experimental evaluations on two typical applications, i.e., cross-modal retrieval and VQA, demonstrate the effectiveness and generalization of our method under multiple kinds of attack scenarios. Moreover, we show that BadCM can robustly evade existing backdoor defenses. Our code is available at https://github.com/xandery-geek/BadCM.