 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIND: Effective Incorrect Assignment Detection through a Multi-Modal Structure-Enhanced Language Model
Paper and Code
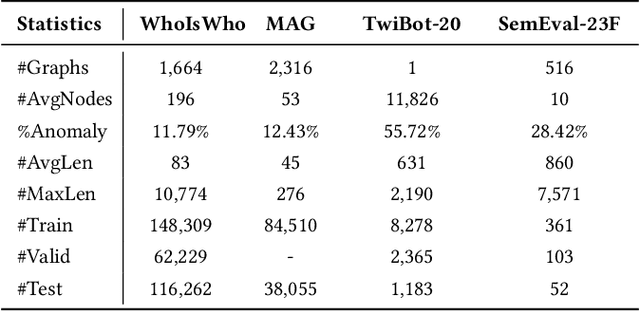
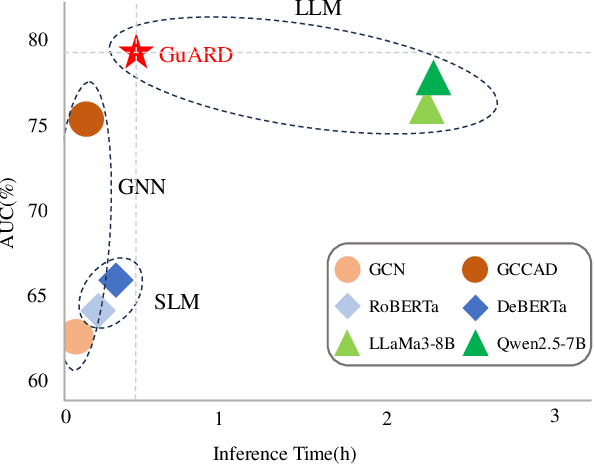
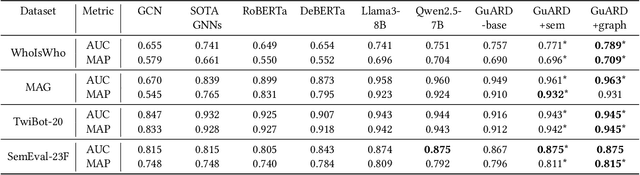
The rapid growth of academic publications has exacerbated the issue of author name ambiguity in online digital libraries. Despite advances in name disambiguation algorithms, cumulative errors continue to undermine the reliability of academic systems. It is estimated that over 10% paper-author assignments are rectified when constructing the million-scale WhoIsWho benchmark. Existing endeavors to detect incorrect assignments are either semantic-based or graph-based approaches, which fall short of making full use of the rich text attributes of papers and implicit structural features defined via the co-occurrence of paper attributes. To this end, this paper introduces a structure-enhanced language model that combines key structural features from graph-based methods with fine-grained semantic features from rich paper attributes to detect incorrect assignments. The proposed model is trained with a highly effective multi-modal multi-turn instruction tuning framework, which incorporates task-guided instruction tuning, text-attribute modality, and structural modality. Experimental results demonstrate that our model outperforms previous approaches, achieving top performance on the leaderboard of KDD Cup 2024. Our code has been publicly available.