 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Negative Sampling Matter? A Review with Insights into its Theory and Applications
Feb 27, 2024



Negative sampling has swiftly risen to prominence as a focal point of research, with wide-ranging applications spanning machine learning, computer vision, natural language processing, data mining, and recommender systems. This growing interest raises several critical questions: Does negative sampling really matter? Is there a general framework that can incorporate all existing negative sampling methods? In what fields is it applied? Addressing these questions, we propose a general framework that leverages negative sampling. Delving into the history of negative sampling, we trace the development of negative sampling through five evolutionary paths. We dissect and categorize the strategies used to select negative sample candidates, detailing global, local, mini-batch, hop, and memory-based approaches. Our review categorizes current negative sampling methods into five types: static, hard, GAN-based, Auxiliary-based, and In-batch methods, providing a clear structure for understanding negative sampling. Beyond detailed categorization, we highlight the application of negative sampling in various areas, offering insights into its practical benefits. Finally, we briefly discuss open problems and future directions for negative sampling.
Personalized Bundle List Recommendation
Apr 03, 2019
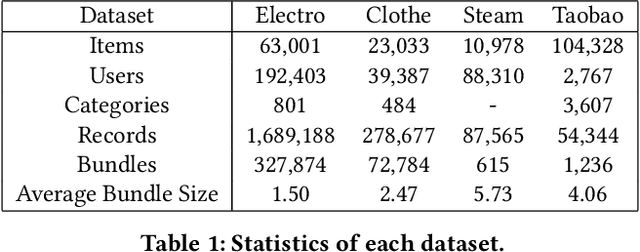
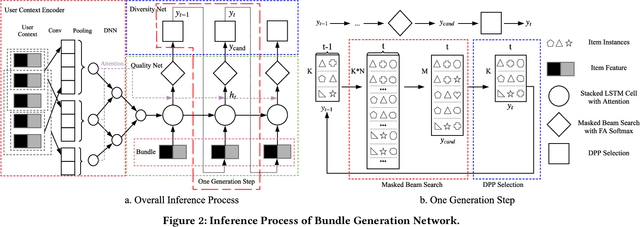
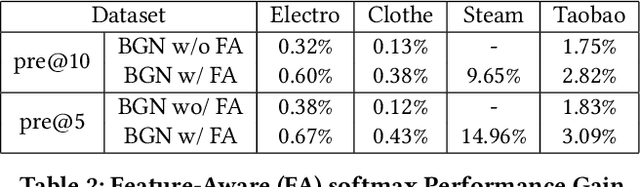
Product bundling, offering a combination of items to customers, is one of the marketing strategies commonly used in online e-commerce and offline retailers. A high-quality bundle generalizes frequent items of interest, and diversity across bundles boosts the user-experience and eventually increases transaction volume. In this paper, we formalize the personalized bundle list recommendation as a structured prediction problem and propose a bundle generation network (BGN), which decomposes the problem into quality/diversity parts by the determinantal point processes (DPPs). BGN uses a typical encoder-decoder framework with a proposed feature-aware softmax to alleviate the inadequate representation of traditional softmax, and integrates the masked beam search and DPP selection to produce high-quality and diversified bundle list with an appropriate bundle size. We conduct extensive experiments on three public datasets and one industrial dataset, including two generated from co-purchase records and the other two extracted from real-world online bundle services. BGN significantly outperforms the state-of-the-art methods in terms of quality, diversity and response time over all datasets. In particular, BGN improves the precision of the best competitors by 16\% on average while maintaining the highest diversity on four datasets, and yields a 3.85x improvement of response time over the best competitors in the bundle list recommendation problem.
ATRank: An Attention-Based User Behavior Modeling Framework for Recommendation
Nov 27, 2017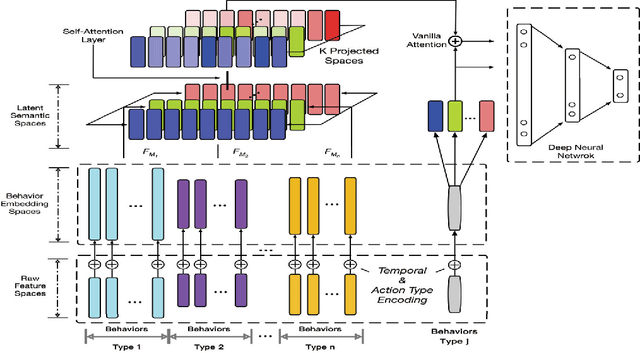
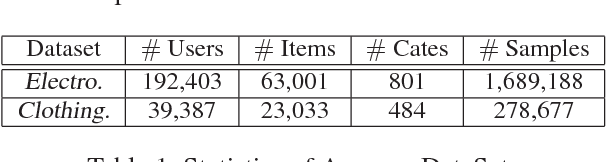
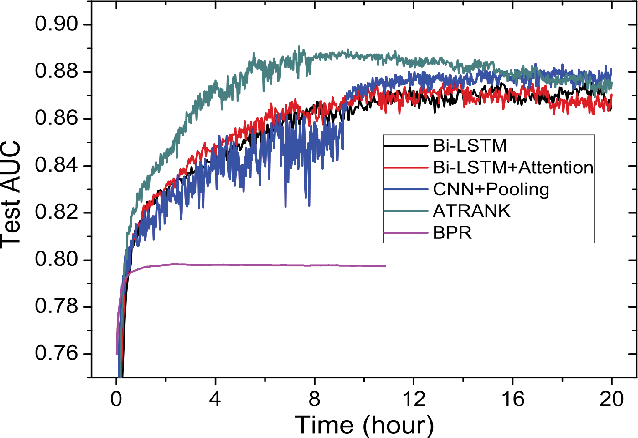

A user can be represented as what he/she does along the history. A common way to deal with the user modeling problem is to manually extract all kinds of aggregated features over the heterogeneous behaviors, which may fail to fully represent the data itself due to limited human instinct. Recent works usually use RNN-based methods to give an overall embedding of a behavior sequence, which then could be exploited by the downstream applications. However, this can only preserve very limited information, or aggregated memories of a person. When a downstream application requires to facilitate the modeled user features, it may lose the integrity of the specific highly correlated behavior of the user, and introduce noises derived from unrelated behaviors. This paper proposes an attention based user behavior modeling framework called ATRank, which we mainly use for recommendation tasks. Heterogeneous user behaviors are considered in our model that we project all types of behaviors into multiple latent semantic spaces, where influence can be made among the behaviors via self-attention. Downstream applications then can use the user behavior vectors via vanilla attention. Experiments show that ATRank can achieve better performance and faster training process. We further explore ATRank to use one unified model to predict different types of user behaviors at the same time, showing a comparable performance with the highly optimized individual models.