 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeb-Scale Academic Name Disambiguation: the WhoIsWho Benchmark, Leaderboard, and Toolkit
Paper and Code
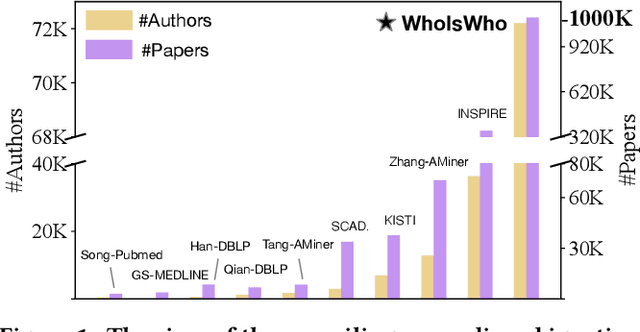

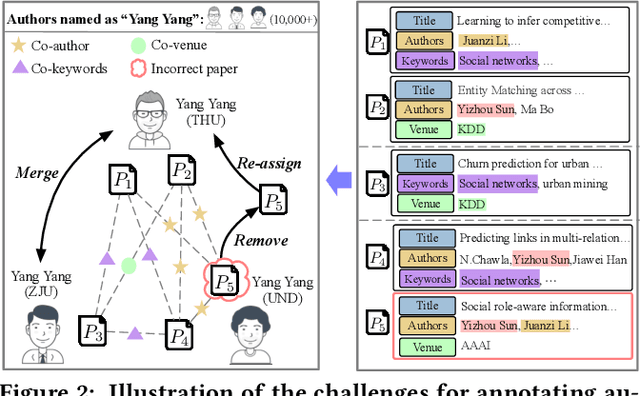
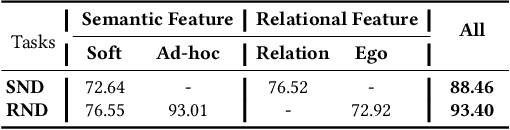
Name disambiguation -- a fundamental problem in online academic systems -- is now facing greater challenges with the increasing growth of research papers. For example, on AMiner, an online academic search platform, about 10% of names own more than 100 authors. Such real-world hard cases cannot be fully addressed by existing research efforts, because of the small-scale or low-quality datasets that they use to build algorithms. The development of effective algorithms is further hampered by a variety of tasks and evaluation protocols designed on top of diverse datasets. To this end, we present WhoIsWho owning, a large-scale benchmark with over 1,000,000 papers built using an interactive annotation process, a regular leaderboard with comprehensive tasks, and an easy-to-use toolkit encapsulating the entire pipeline as well as the most powerful features and baseline models for tackling the tasks. Our developed strong baseline has already been deployed online in the AMiner system to enable daily arXiv paper assignments. The documentation and regular leaderboards are publicly available at http://whoiswho.biendata.xyz/.