 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing the Learning Dynamics of Long-Context Continual Pre-training
Apr 03, 2026Existing studies on Long-Context Continual Pre-training (LCCP) mainly focus on small-scale models and limited data regimes (tens of billions of tokens). We argue that directly migrating these small-scale settings to industrial-grade models risks insufficient adaptation and premature training termination. Furthermore, current evaluation methods rely heavily on downstream benchmarks (e.g., Needle-in-a-Haystack), which often fail to reflect the intrinsic convergence state and can lead to "deceptive saturation". In this paper, we present the first systematic investigation of LCCP learning dynamics using the industrial-grade Hunyuan-A13B (80B total parameters), tracking its evolution across a 200B-token training trajectory. Specifically, we propose a hierarchical framework to analyze LCCP dynamics across behavioral (supervised fine-tuning probing), probabilistic (perplexity), and mechanistic (attention patterns) levels. Our findings reveal: (1) Necessity of Massive Data Scaling: Training regimes of dozens of billions of tokens are insufficient for industrial-grade LLMs' LCCP (e.g., Hunyuan-A13B reaches saturation after training over 150B tokens). (2) Deceptive Saturation vs. Intrinsic Saturation: Traditional NIAH scores report "fake saturation" early, while our PPL-based analysis reveals continuous intrinsic improvements and correlates more strongly with downstream performance. (3) Mechanistic Monitoring for Training Stability: Retrieval heads act as efficient, low-resource training monitors, as their evolving attention scores reliably track LCCP progress and exhibit high correlation with SFT results. This work provides a comprehensive monitoring framework, evaluation system, and mechanistic interpretation for the LCCP of industrial-grade LLM.
Probing How Scalable Table Data Enhances General Long-Context Reasoning
Mar 23, 2026As real-world tasks grow increasingly complex, long-context reasoning has become a core capability for Large Language Models (LLMs). However, few studies explore which data types are effective for long-context reasoning and why. We find that structured table data with periodic structures shows strong potential for long-context reasoning. Motivated by this observation, we mathematically analyze tabular dependency structures using mutual information, revealing periodic non-vanishing dependencies in table data. Furthermore, we systematically analyze the capabilities of structured table data, conduct relevant scaling experiments, and validate its underlying mechanisms for enhancing long-context reasoning, yielding several meaningful insights. Leveraging these insights, we propose a simple yet scalable pipeline(TableLong) for synthesizing high-quality, diverse, and verifiable structured table data to boost long-context reasoning via RL. Extensive experimental results demonstrate that table data significantly enhances the long-context reasoning capability of LLMs across multiple long-context benchmarks (+8.24\% on average), and even improves performance on out-of-domain benchmarks (+8.06\% on average). We hope that our insights provide practical guidance for effective post-training data to enhance long-context reasoning in LLMs.
CL-bench: A Benchmark for Context Learning
Feb 03, 2026Current language models (LMs) excel at reasoning over prompts using pre-trained knowledge. However, real-world tasks are far more complex and context-dependent: models must learn from task-specific context and leverage new knowledge beyond what is learned during pre-training to reason and resolve tasks. We term this capability context learning, a crucial ability that humans naturally possess but has been largely overlooked. To this end, we introduce CL-bench, a real-world benchmark consisting of 500 complex contexts, 1,899 tasks, and 31,607 verification rubrics, all crafted by experienced domain experts. Each task is designed such that the new content required to resolve it is contained within the corresponding context. Resolving tasks in CL-bench requires models to learn from the context, ranging from new domain-specific knowledge, rule systems, and complex procedures to laws derived from empirical data, all of which are absent from pre-training. This goes far beyond long-context tasks that primarily test retrieval or reading comprehension, and in-context learning tasks, where models learn simple task patterns via instructions and demonstrations. Our evaluations of ten frontier LMs find that models solve only 17.2% of tasks on average. Even the best-performing model, GPT-5.1, solves only 23.7%, revealing that LMs have yet to achieve effective context learning, which poses a critical bottleneck for tackling real-world, complex context-dependent tasks. CL-bench represents a step towards building LMs with this fundamental capability, making them more intelligent and advancing their deployment in real-world scenarios.
Electrically functionalized body surface for deep-tissue bioelectrical recording
Dec 04, 2024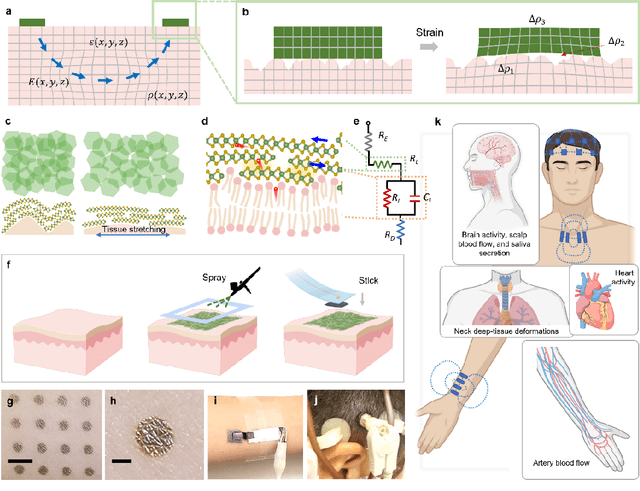
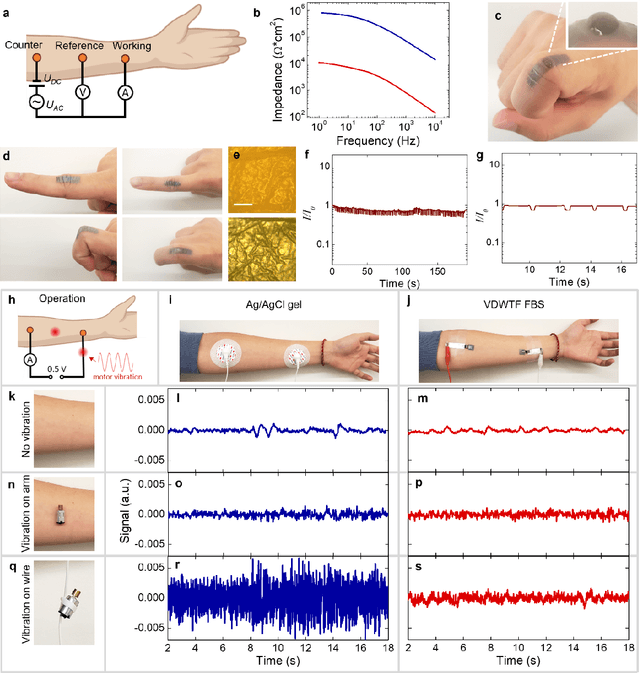
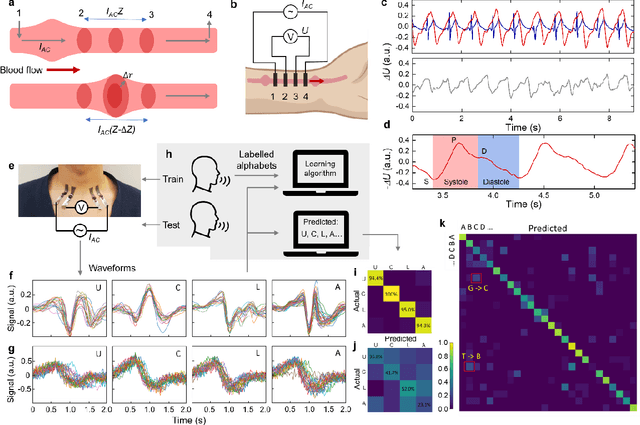
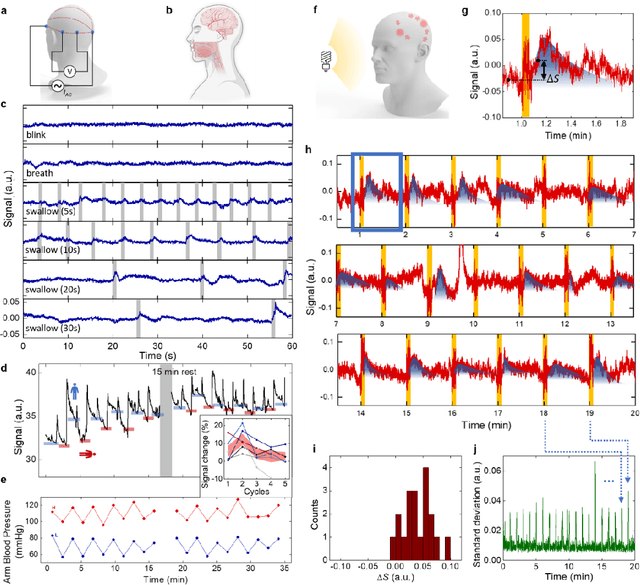
Directly probing deep tissue activities from body surfaces offers a noninvasive approach to monitoring essential physiological processes1-3. However, this method is technically challenged by rapid signal attenuation toward the body surface and confounding motion artifacts4-6 primarily due to excessive contact impedance and mechanical mismatch with conventional electrodes. Herein, by formulating and directly spray coating biocompatible two-dimensional nanosheet ink onto the human body under ambient conditions, we create microscopically conformal and adaptive van der Waals thin films (VDWTFs) that seamlessly merge with non-Euclidean, hairy, and dynamically evolving body surfaces. Unlike traditional deposition methods, which often struggle with conformality and adaptability while retaining high electronic performance, this gentle process enables the formation of high-performance VDWTFs directly on the body surface under bio-friendly conditions, making it ideal for biological applications. This results in low-impedance electrically functionalized body surfaces (EFBS), enabling highly robust monitoring of biopotential and bioimpedance modulations associated with deep-tissue activities, such as blood circulation, muscle movements, and brain activities. Compared to commercial solutions, our VDWTF-EFBS exhibits nearly two-orders of magnitude lower contact impedance and substantially reduces the extrinsic motion artifacts, enabling reliable extraction of bioelectrical signals from irregular surfaces, such as unshaved human scalps. This advancement defines a technology for continuous, noninvasive monitoring of deep-tissue activities during routine body movements.
Eval-GCSC: A New Metric for Evaluating ChatGPT's Performance in Chinese Spelling Correction
Nov 14, 2023



ChatGPT has demonstrated impressive performance in various downstream tasks. However, in the Chinese Spelling Correction (CSC) task, we observe a discrepancy: while ChatGPT performs well under human evaluation, it scores poorly according to traditional metrics. We believe this inconsistency arises because the traditional metrics are not well-suited for evaluating generative models. Their overly strict length and phonics constraints may lead to underestimating ChatGPT's correction capabilities. To better evaluate generative models in the CSC task, this paper proposes a new evaluation metric: Eval-GCSC. By incorporating word-level and semantic similarity judgments, it relaxes the stringent length and phonics constraints. Experimental results show that Eval-GCSC closely aligns with human evaluations. Under this metric, ChatGPT's performance is comparable to traditional token-level classification models (TCM), demonstrating its potential as a CSC tool. The source code and scripts can be accessed at https://github.com/ktlKTL/Eval-GCSC.
Combining Self-Training and Self-Supervised Learning for Unsupervised Disfluency Detection
Oct 29, 2020
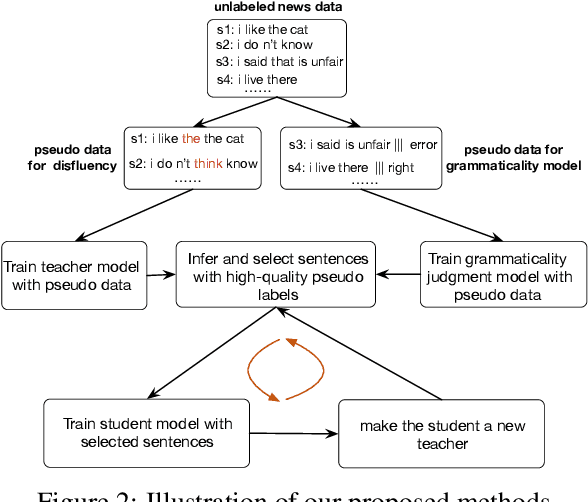
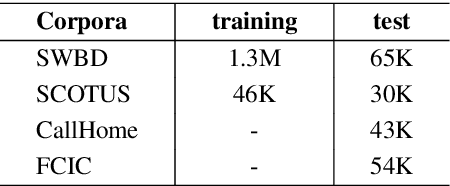
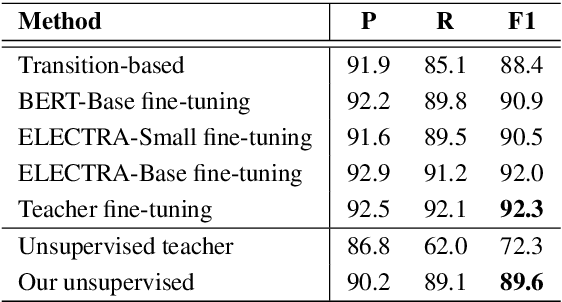
Most existing approaches to disfluency detection heavily rely on human-annotated corpora, which is expensive to obtain in practice. There have been several proposals to alleviate this issue with, for instance, self-supervised learning techniques, but they still require human-annotated corpora. In this work, we explore the unsupervised learning paradigm which can potentially work with unlabeled text corpora that are cheaper and easier to obtain. Our model builds upon the recent work on Noisy Student Training, a semi-supervised learning approach that extends the idea of self-training. Experimental results on the commonly used English Switchboard test set show that our approach achieves competitive performance compared to the previous state-of-the-art supervised systems using contextualized word embeddings (e.g. BERT and ELECTRA).
Multi-Task Self-Supervised Learning for Disfluency Detection
Aug 15, 2019
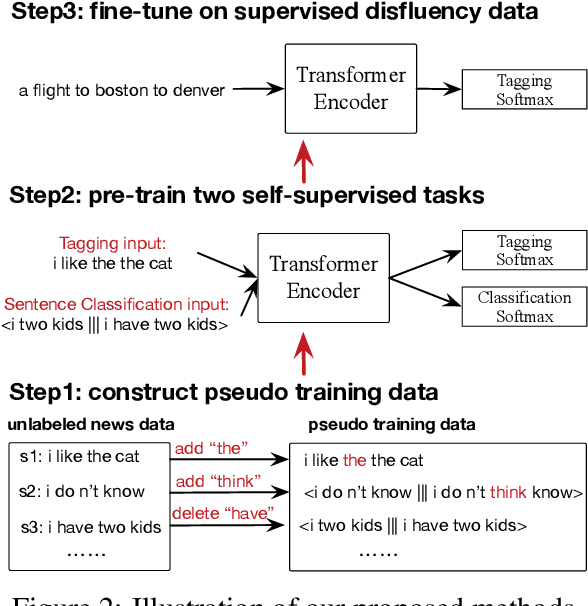
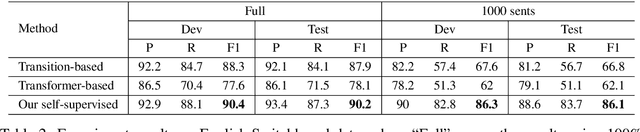
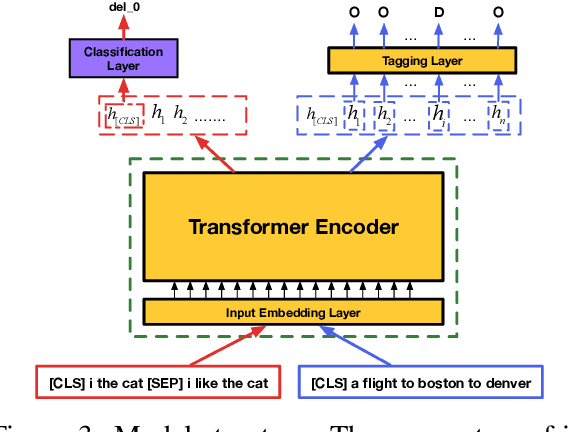
Most existing approaches to disfluency detection heavily rely on human-annotated data, which is expensive to obtain in practice. To tackle the training data bottleneck, we investigate methods for combining multiple self-supervised tasks-i.e., supervised tasks where data can be collected without manual labeling. First, we construct large-scale pseudo training data by randomly adding or deleting words from unlabeled news data, and propose two self-supervised pre-training tasks: (i) tagging task to detect the added noisy words. (ii) sentence classification to distinguish original sentences from grammatically-incorrect sentences. We then combine these two tasks to jointly train a network. The pre-trained network is then fine-tuned using human-annotated disfluency detection training data. Experimental results on the commonly used English Switchboard test set show that our approach can achieve competitive performance compared to the previous systems (trained using the full dataset) by using less than 1% (1000 sentences) of the training data. Our method trained on the full dataset significantly outperforms previous methods, reducing the error by 21% on English Switchboard.