 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC-LLM: Learn to Check Chinese Spelling Errors Character by Character
Jun 24, 2024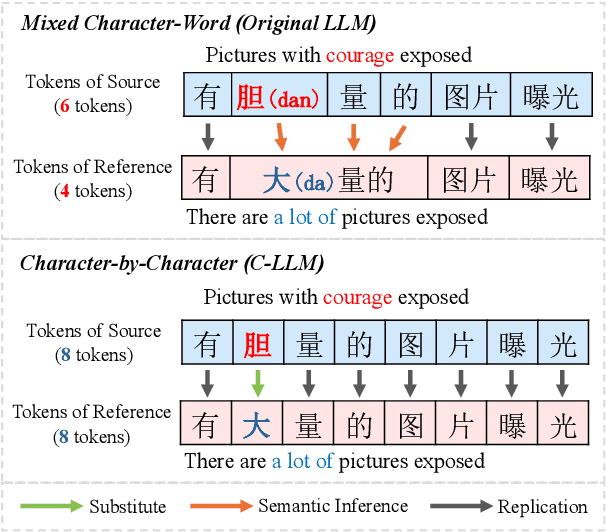
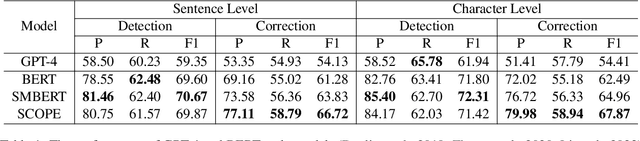
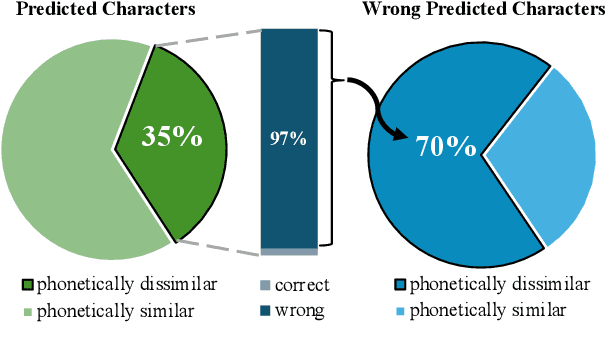
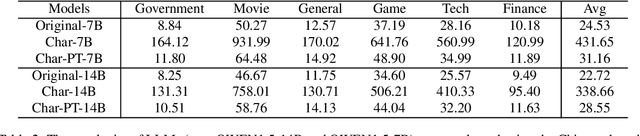
Chinese Spell Checking (CSC) aims to detect and correct spelling errors in sentences. Despite Large Language Models (LLMs) exhibit robust capabilities and are widely applied in various tasks, their performance on CSC is often unsatisfactory. We find that LLMs fail to meet the Chinese character-level constraints of the CSC task, namely equal length and phonetic similarity, leading to a performance bottleneck. Further analysis reveal that this issue stems from the granularity of tokenization, as current mixed character-word tokenization struggles to satisfy these character-level constraints. To address this issue, we propose C-LLM, a Large Language Model-based Chinese Spell Checking method that learns to check errors Character by Character. Character-level tokenization enables the model to learn character-level alignment, effectively mitigating issues related to character-level constraints. Furthermore, CSC is simplified to replication-dominated and substitution-supplemented tasks. Experiments on two CSC benchmarks demonstrate that C-LLM achieves an average improvement of 10% over existing methods. Specifically, it shows a 2.1% improvement in general scenarios and a significant 12% improvement in vertical domain scenarios, establishing state-of-the-art performance. The source code can be accessed at https://github.com/ktlKTL/C-LLM.
Eval-GCSC: A New Metric for Evaluating ChatGPT's Performance in Chinese Spelling Correction
Nov 14, 2023



ChatGPT has demonstrated impressive performance in various downstream tasks. However, in the Chinese Spelling Correction (CSC) task, we observe a discrepancy: while ChatGPT performs well under human evaluation, it scores poorly according to traditional metrics. We believe this inconsistency arises because the traditional metrics are not well-suited for evaluating generative models. Their overly strict length and phonics constraints may lead to underestimating ChatGPT's correction capabilities. To better evaluate generative models in the CSC task, this paper proposes a new evaluation metric: Eval-GCSC. By incorporating word-level and semantic similarity judgments, it relaxes the stringent length and phonics constraints. Experimental results show that Eval-GCSC closely aligns with human evaluations. Under this metric, ChatGPT's performance is comparable to traditional token-level classification models (TCM), demonstrating its potential as a CSC tool. The source code and scripts can be accessed at https://github.com/ktlKTL/Eval-GCSC.