 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Retrieval Augmented Multi-modal Generation: A Benchmark, Evaluate Metrics and Strong Baselines
Paper and Code

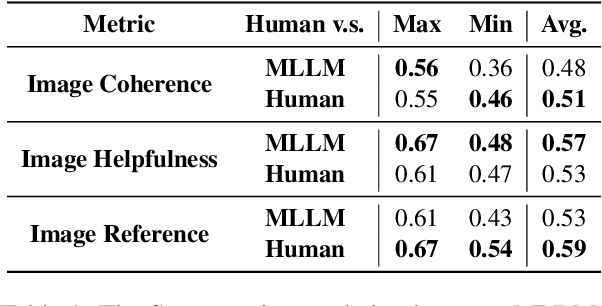
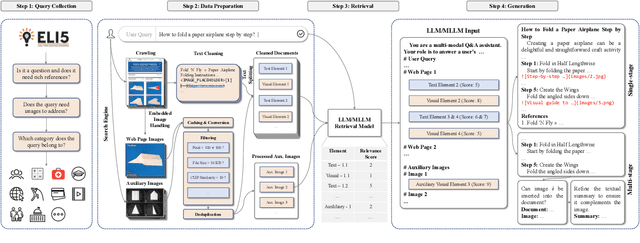
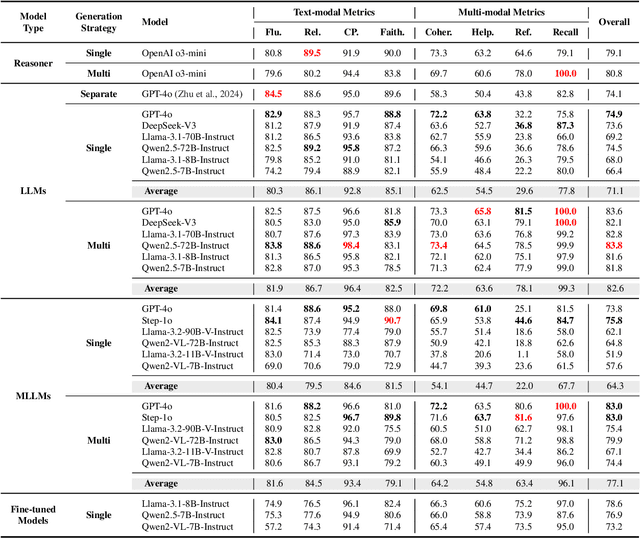
This paper investigates an intriguing task of Multi-modal Retrieval Augmented Multi-modal Generation (M$^2$RAG). This task requires foundation models to browse multi-modal web pages, with mixed text and images, and generate multi-modal responses for solving user queries, which exhibits better information density and readability. Given the early researching stage of M$^2$RAG task, there is a lack of systematic studies and analysis. To fill this gap, we construct a benchmark for M$^2$RAG task, equipped with a suite of text-modal metrics and multi-modal metrics to analyze the capabilities of existing foundation models. Besides, we also propose several effective methods for foundation models to accomplish this task, based on the comprehensive evaluation results on our benchmark. Extensive experimental results reveal several intriguing phenomena worth further research.