 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Exact Match: Semantically Reassessing Event Extraction by Large Language Models
Paper and Code

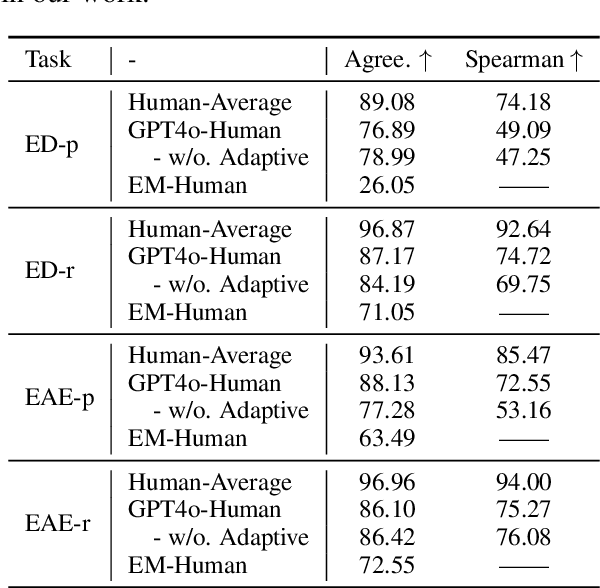
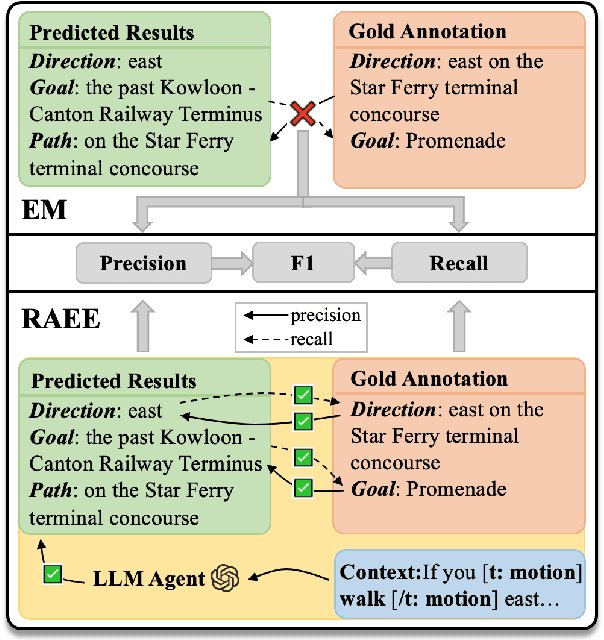

Event extraction has gained extensive research attention due to its broad range of applications. However, the current mainstream evaluation method for event extraction relies on token-level exact match, which misjudges numerous semantic-level correct cases. This reliance leads to a significant discrepancy between the evaluated performance of models under exact match criteria and their real performance. To address this problem, we propose RAEE, an automatic evaluation framework that accurately assesses event extraction results at semantic-level instead of token-level. Specifically, RAEE leverages Large Language Models (LLMs) as automatic evaluation agents, incorporating chain-of-thought prompting and an adaptive mechanism to achieve interpretable and adaptive evaluations for precision and recall of triggers and arguments. Extensive experimental results demonstrate that: (1) RAEE achieves a very high correlation with the human average; (2) after reassessing 14 models, including advanced LLMs, on 10 datasets, there is a significant performance gap between exact match and RAEE. The exact match evaluation significantly underestimates the performance of existing event extraction models, particularly underestimating the capabilities of LLMs; (3) fine-grained analysis under RAEE evaluation reveals insightful phenomena worth further exploration. The evaluation toolkit of our proposed RAEE will be publicly released.