 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Long-Context Language Models Better Multi-Hop Reasoners
Aug 06, 2024
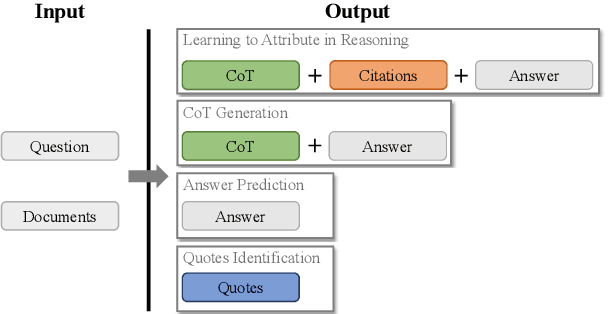
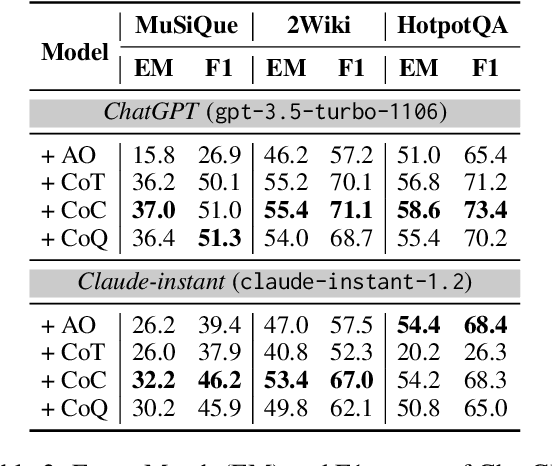
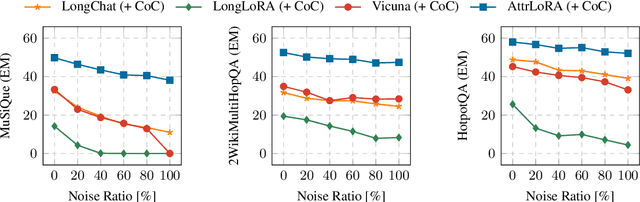
Recent advancements in long-context modeling have enhanced language models (LMs) for complex tasks across multiple NLP applications. Despite this progress, we find that these models struggle with multi-hop reasoning and exhibit decreased performance in the presence of noisy contexts. In this paper, we introduce Reasoning with Attributions, a novel approach that prompts LMs to supply attributions for each assertion during their reasoning. We validate our approach through experiments on three multi-hop datasets, employing both proprietary and open-source models, and demonstrate its efficacy and resilience. Furthermore, we explore methods to augment reasoning capabilities via fine-tuning and offer an attribution-annotated dataset and a specialized training strategy. Our fine-tuned model achieves competitive performance on multi-hop reasoning benchmarks, closely paralleling proprietary LMs such as ChatGPT and Claude-instant.
STAGE: Span Tagging and Greedy Inference Scheme for Aspect Sentiment Triplet Extraction
Nov 29, 2022
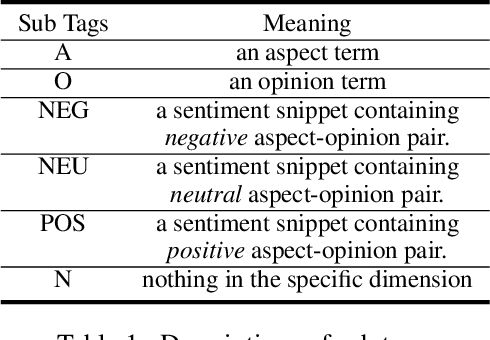


Aspect Sentiment Triplet Extraction (ASTE) has become an emerging task in sentiment analysis research, aiming to extract triplets of the aspect term, its corresponding opinion term, and its associated sentiment polarity from a given sentence. Recently, many neural networks based models with different tagging schemes have been proposed, but almost all of them have their limitations: heavily relying on 1) prior assumption that each word is only associated with a single role (e.g., aspect term, or opinion term, etc. ) and 2) word-level interactions and treating each opinion/aspect as a set of independent words. Hence, they perform poorly on the complex ASTE task, such as a word associated with multiple roles or an aspect/opinion term with multiple words. Hence, we propose a novel approach, Span TAgging and Greedy infErence (STAGE), to extract sentiment triplets in span-level, where each span may consist of multiple words and play different roles simultaneously. To this end, this paper formulates the ASTE task as a multi-class span classification problem. Specifically, STAGE generates more accurate aspect sentiment triplet extractions via exploring span-level information and constraints, which consists of two components, namely, span tagging scheme and greedy inference strategy. The former tag all possible candidate spans based on a newly-defined tagging set. The latter retrieves the aspect/opinion term with the maximum length from the candidate sentiment snippet to output sentiment triplets. Furthermore, we propose a simple but effective model based on the STAGE, which outperforms the state-of-the-arts by a large margin on four widely-used datasets. Moreover, our STAGE can be easily generalized to other pair/triplet extraction tasks, which also demonstrates the superiority of the proposed scheme STAGE.
BiSyn-GAT+: Bi-Syntax Aware Graph Attention Network for Aspect-based Sentiment Analysis
Apr 06, 2022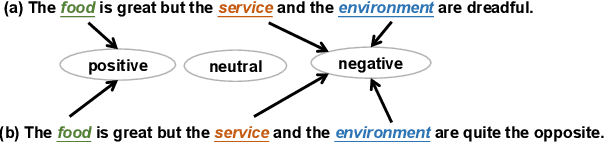
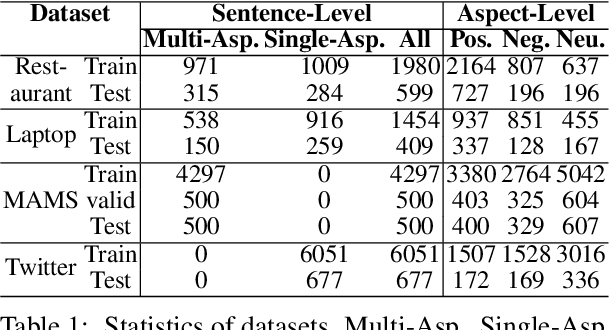
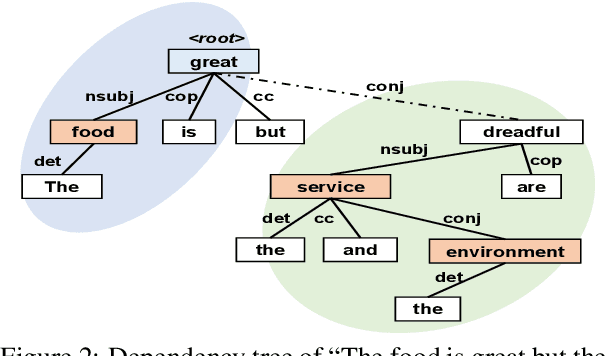
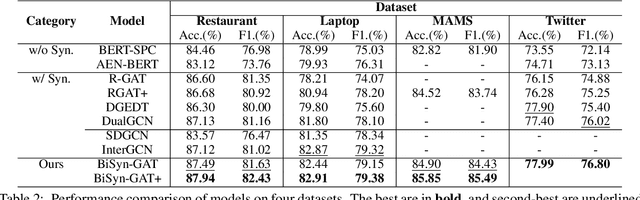
Aspect-based sentiment analysis (ABSA) is a fine-grained sentiment analysis task that aims to align aspects and corresponding sentiments for aspect-specific sentiment polarity inference. It is challenging because a sentence may contain multiple aspects or complicated (e.g., conditional, coordinating, or adversative) relations. Recently, exploiting dependency syntax information with graph neural networks has been the most popular trend. Despite its success, methods that heavily rely on the dependency tree pose challenges in accurately modeling the alignment of the aspects and their words indicative of sentiment, since the dependency tree may provide noisy signals of unrelated associations (e.g., the "conj" relation between "great" and "dreadful" in Figure 2). In this paper, to alleviate this problem, we propose a Bi-Syntax aware Graph Attention Network (BiSyn-GAT+). Specifically, BiSyn-GAT+ fully exploits the syntax information (e.g., phrase segmentation and hierarchical structure) of the constituent tree of a sentence to model the sentiment-aware context of every single aspect (called intra-context) and the sentiment relations across aspects (called inter-context) for learning. Experiments on four benchmark datasets demonstrate that BiSyn-GAT+ outperforms the state-of-the-art methods consistently.