 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiSyn-GAT+: Bi-Syntax Aware Graph Attention Network for Aspect-based Sentiment Analysis
Apr 06, 2022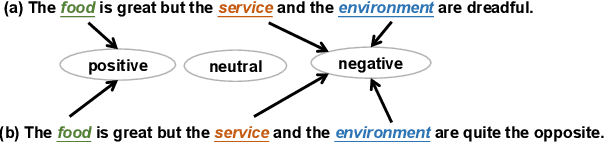
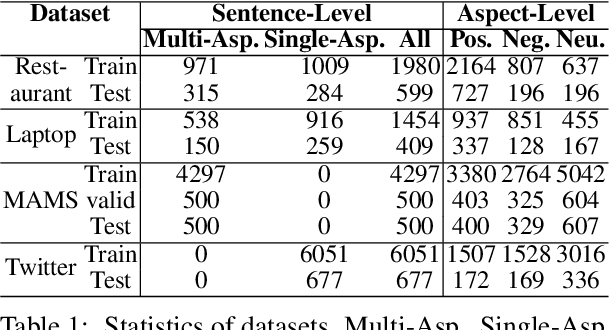
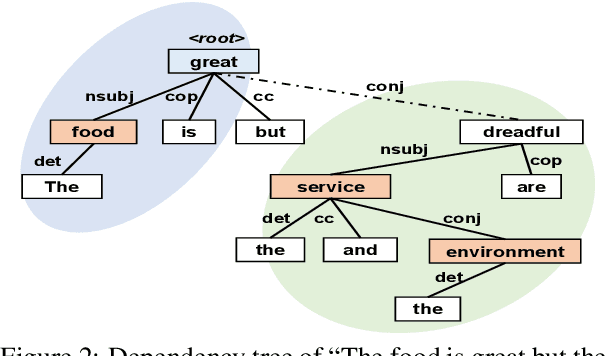
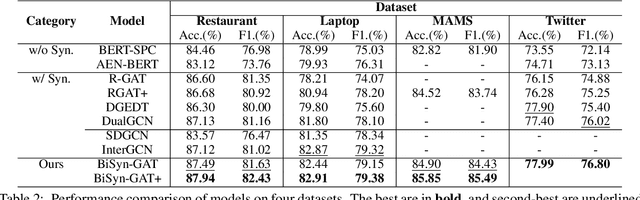
Aspect-based sentiment analysis (ABSA) is a fine-grained sentiment analysis task that aims to align aspects and corresponding sentiments for aspect-specific sentiment polarity inference. It is challenging because a sentence may contain multiple aspects or complicated (e.g., conditional, coordinating, or adversative) relations. Recently, exploiting dependency syntax information with graph neural networks has been the most popular trend. Despite its success, methods that heavily rely on the dependency tree pose challenges in accurately modeling the alignment of the aspects and their words indicative of sentiment, since the dependency tree may provide noisy signals of unrelated associations (e.g., the "conj" relation between "great" and "dreadful" in Figure 2). In this paper, to alleviate this problem, we propose a Bi-Syntax aware Graph Attention Network (BiSyn-GAT+). Specifically, BiSyn-GAT+ fully exploits the syntax information (e.g., phrase segmentation and hierarchical structure) of the constituent tree of a sentence to model the sentiment-aware context of every single aspect (called intra-context) and the sentiment relations across aspects (called inter-context) for learning. Experiments on four benchmark datasets demonstrate that BiSyn-GAT+ outperforms the state-of-the-art methods consistently.
Exploiting Global Contextual Information for Document-level Named Entity Recognition
Jun 02, 2021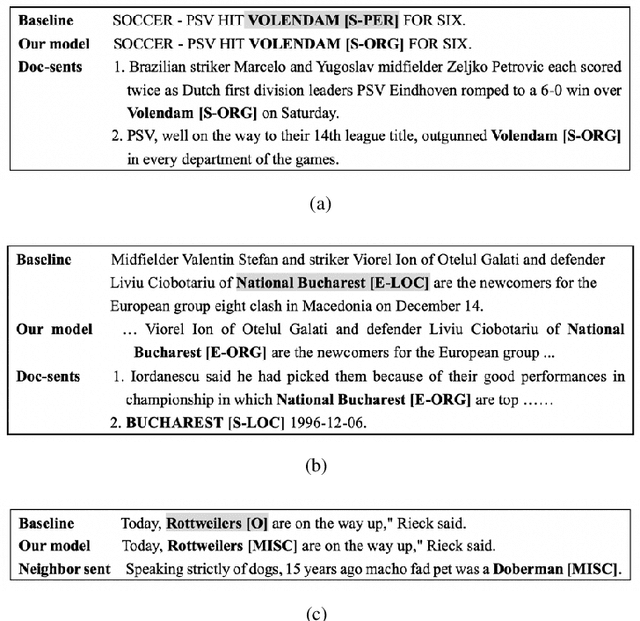
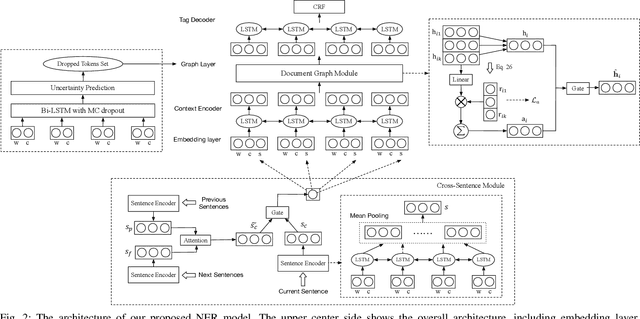

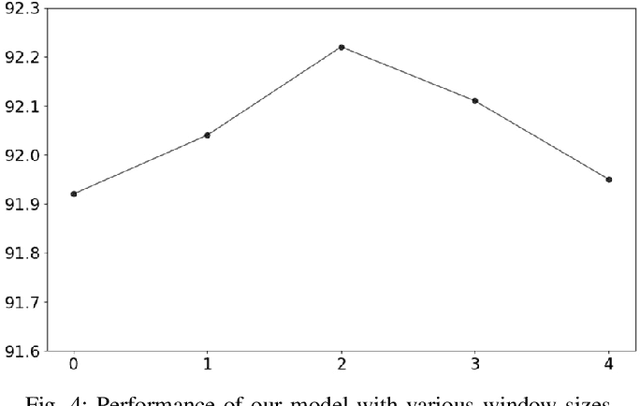
Most existing named entity recognition (NER) approaches are based on sequence labeling models, which focus on capturing the local context dependencies. However, the way of taking one sentence as input prevents the modeling of non-sequential global context, which is useful especially when local context information is limited or ambiguous. To this end, we propose a model called Global Context enhanced Document-level NER (GCDoc) to leverage global contextual information from two levels, i.e., both word and sentence. At word-level, a document graph is constructed to model a wider range of dependencies between words, then obtain an enriched contextual representation for each word via graph neural networks (GNN). To avoid the interference of noise information, we further propose two strategies. First we apply the epistemic uncertainty theory to find out tokens whose representations are less reliable, thereby helping prune the document graph. Then a selective auxiliary classifier is proposed to effectively learn the weight of edges in document graph and reduce the importance of noisy neighbour nodes. At sentence-level, for appropriately modeling wider context beyond single sentence, we employ a cross-sentence module which encodes adjacent sentences and fuses it with the current sentence representation via attention and gating mechanisms. Extensive experiments on two benchmark NER datasets (CoNLL 2003 and Ontonotes 5.0 English dataset) demonstrate the effectiveness of our proposed model. Our model reaches F1 score of 92.22 (93.40 with BERT) on CoNLL 2003 dataset and 88.32 (90.49 with BERT) on Ontonotes 5.0 dataset, achieving new state-of-the-art performance.
A Survey on Recent Advances in Sequence Labeling from Deep Learning Models
Nov 13, 2020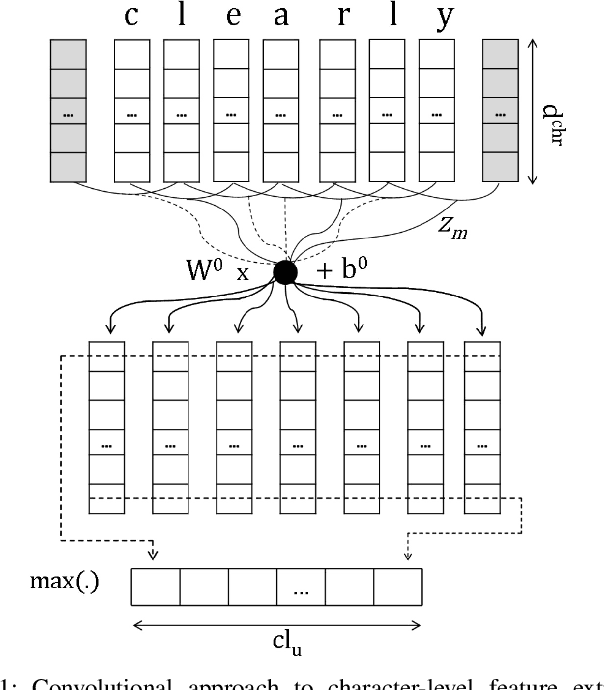
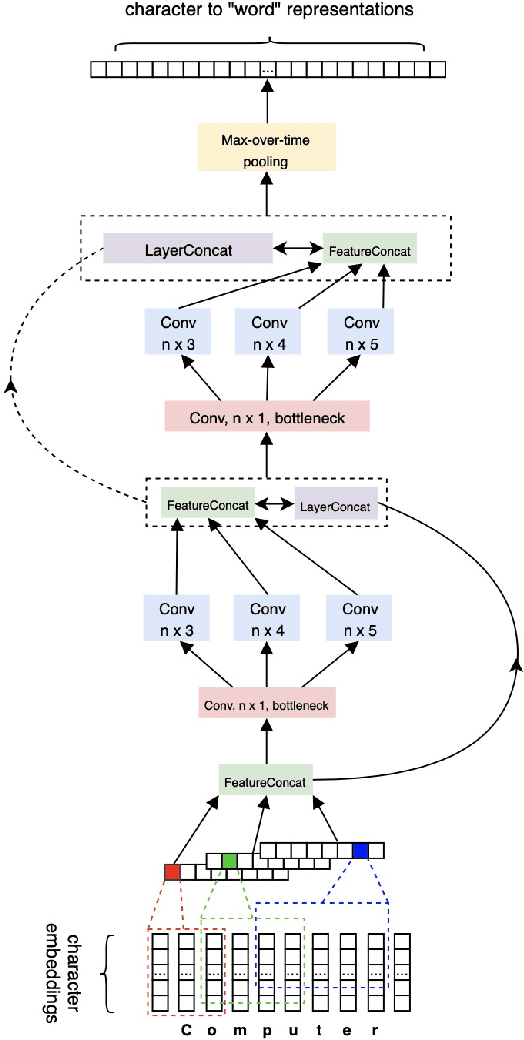
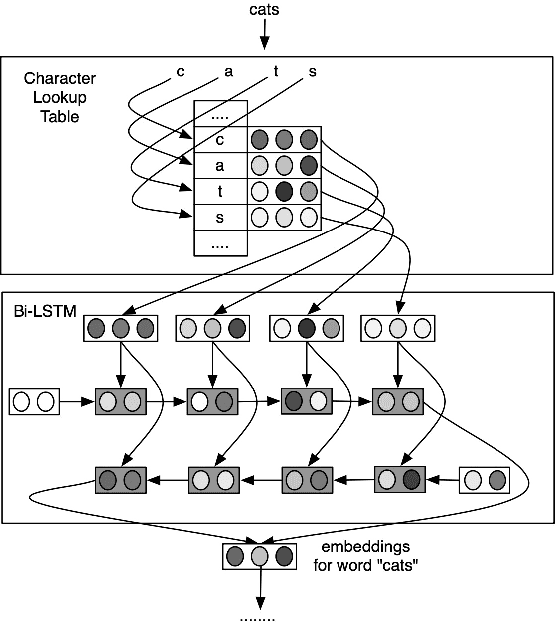
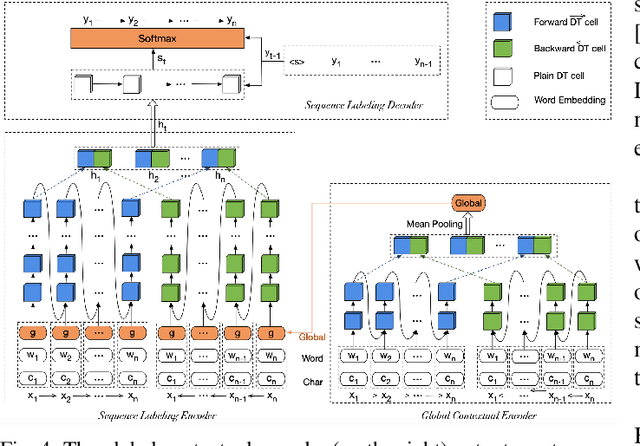
Sequence labeling (SL) is a fundamental research problem encompassing a variety of tasks, e.g., part-of-speech (POS) tagging, named entity recognition (NER), text chunking, etc. Though prevalent and effective in many downstream applications (e.g., information retrieval, question answering, and knowledge graph embedding), conventional sequence labeling approaches heavily rely on hand-crafted or language-specific features. Recently, deep learning has been employed for sequence labeling tasks due to its powerful capability in automatically learning complex features of instances and effectively yielding the stat-of-the-art performances. In this paper, we aim to present a comprehensive review of existing deep learning-based sequence labeling models, which consists of three related tasks, e.g., part-of-speech tagging, named entity recognition, and text chunking. Then, we systematically present the existing approaches base on a scientific taxonomy, as well as the widely-used experimental datasets and popularly-adopted evaluation metrics in the SL domain. Furthermore, we also present an in-depth analysis of different SL models on the factors that may affect the performance and future directions in the SL domain.