 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDASNet: Dynamic Activation Sparsity for Neural Network Efficiency Improvement
Paper and Code
Sep 13, 2019
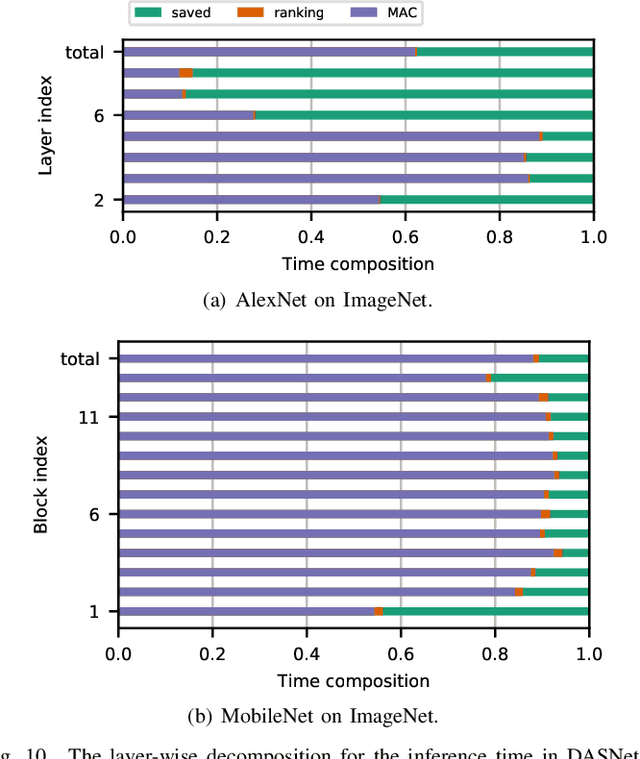
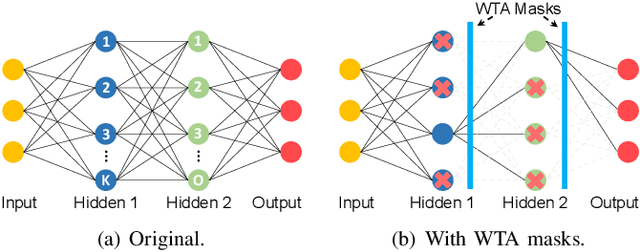
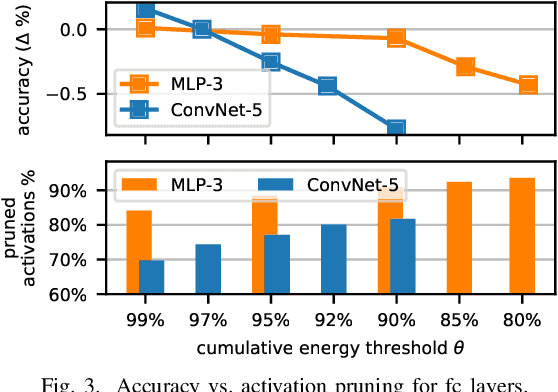
To improve the execution speed and efficiency of neural networks in embedded systems, it is crucial to decrease the model size and computational complexity. In addition to conventional compression techniques, e.g., weight pruning and quantization, removing unimportant activations can reduce the amount of data communication and the computation cost. Unlike weight parameters, the pattern of activations is directly related to input data and thereby changes dynamically. To regulate the dynamic activation sparsity (DAS), in this work, we propose a generic low-cost approach based on winners-take-all (WTA) dropout technique. The network enhanced by the proposed WTA dropout, namely \textit{DASNet}, features structured activation sparsity with an improved sparsity level. Compared to the static feature map pruning methods, DASNets provide better computation cost reduction. The WTA technique can be easily applied in deep neural networks without incurring additional training variables. More importantly, DASNet can be seamlessly integrated with other compression techniques, such as weight pruning and quantization, without compromising on accuracy. Our experiments on various networks and datasets present significant run-time speedups with negligible accuracy loss.