 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Single-gated Mixtures of Experts
Paper and Code
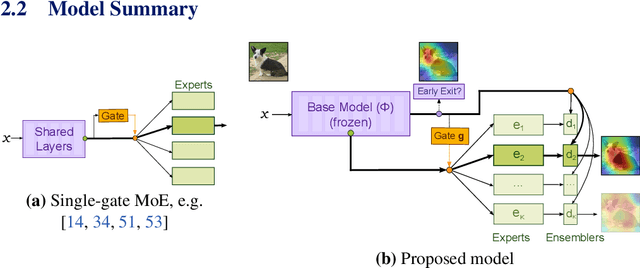
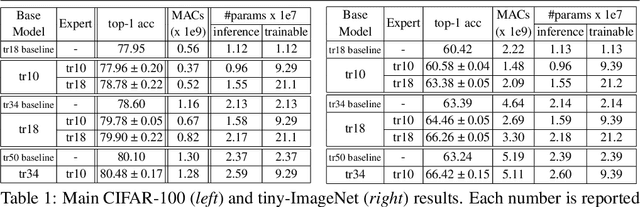
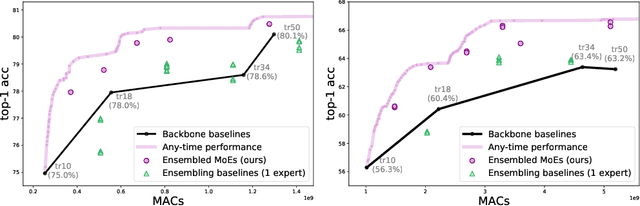
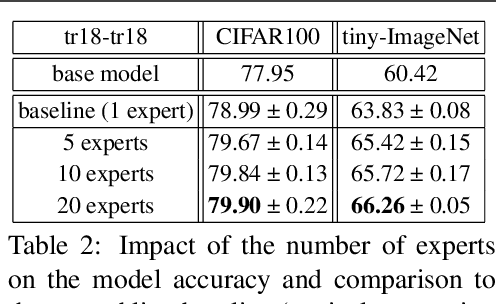
Mixture of Experts (MoE) are rising in popularity as a means to train extremely large-scale models, yet allowing for a reasonable computational cost at inference time. Recent state-of-the-art approaches usually assume a large number of experts, and require training all experts jointly, which often lead to training instabilities such as the router collapsing In contrast, in this work, we propose to revisit the simple single-gate MoE, which allows for more practical training. Key to our work are (i) a base model branch acting both as an early-exit and an ensembling regularization scheme, (ii) a simple and efficient asynchronous training pipeline without router collapse issues, and finally (iii) a per-sample clustering-based initialization. We show experimentally that the proposed model obtains efficiency-to-accuracy trade-offs comparable with other more complex MoE, and outperforms non-mixture baselines. This showcases the merits of even a simple single-gate MoE, and motivates further exploration in this area.