 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeception for Complex Action Recognition
Paper and Code
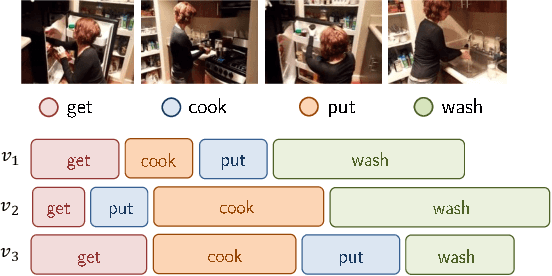
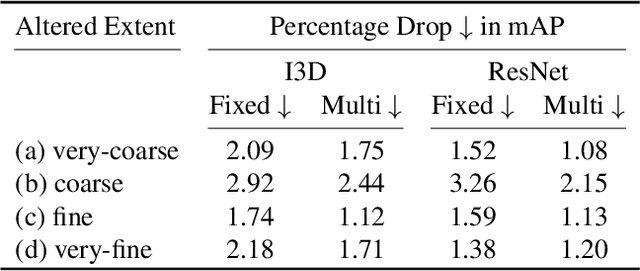
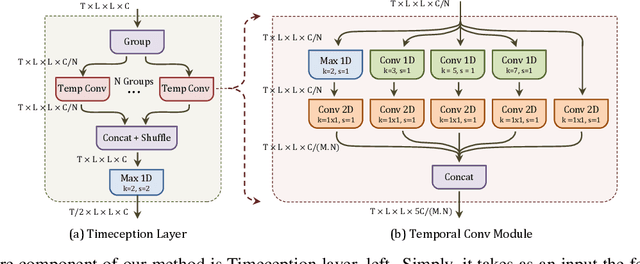
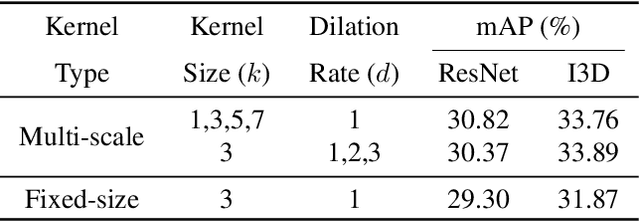
This paper focuses on the temporal aspect for recognizing human activities in videos; an important visual cue that has long been either disregarded or ill-used. We revisit the conventional definition of an activity and restrict it to "Complex Action": a set of one-actions with a weak temporal pattern that serves a specific purpose. Related works use spatiotemporal 3D convolutions with fixed kernel size, too rigid to capture the varieties in temporal extents of complex actions, and too short for long-range temporal modeling. In contrast, we use multi-scale temporal convolutions, and we reduce the complexity of 3D convolutions. The outcome is Timeception convolution layers, which reasons about minute-long temporal patterns, a factor of 8 longer than best related works. As a result, Timeception achieves impressive accuracy in recognizing human activities of Charades. Further, we conduct analysis to demonstrate that Timeception learns long-range temporal dependencies and tolerate temporal extents of complex actions.