Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKPRNet: Improving projection-based LiDAR semantic segmentation
Paper and Code
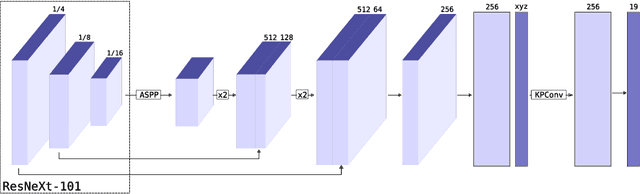
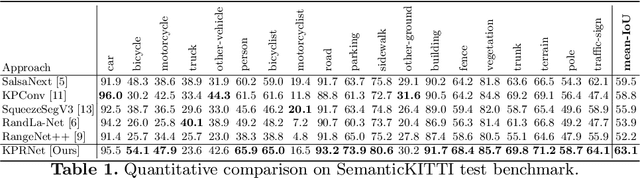
Semantic segmentation is an important component in the perception systems of autonomous vehicles. In this work, we adopt recent advances in both image and point cloud segmentation to achieve a better accuracy in the task of segmenting LiDAR scans. KPRNet improves the convolutional neural network architecture of 2D projection methods and utilizes KPConv to replace the commonly used post-processing techniques with a learnable point-wise component which allows us to obtain more accurate 3D labels. With these improvements our model outperforms the current best method on the SemanticKITTI benchmark, reaching an mIoU of 63.1.
* "ECCV 2020. Code and pre-trained models at
https://github.com/DeyvidKochanov-TomTom/kprnet"
View paper on