 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial-aware Vision Language Model for Autonomous Driving
Dec 30, 2025While Vision-Language Models (VLMs) show significant promise for end-to-end autonomous driving by leveraging the common sense embedded in language models, their reliance on 2D image cues for complex scene understanding and decision-making presents a critical bottleneck for safety and reliability. Current image-based methods struggle with accurate metric spatial reasoning and geometric inference, leading to unreliable driving policies. To bridge this gap, we propose LVLDrive (LiDAR-Vision-Language), a novel framework specifically designed to upgrade existing VLMs with robust 3D metric spatial understanding for autonomous driving by incoperating LiDAR point cloud as an extra input modality. A key challenge lies in mitigating the catastrophic disturbance introduced by disparate 3D data to the pre-trained VLMs. To this end, we introduce a Gradual Fusion Q-Former that incrementally injects LiDAR features, ensuring the stability and preservation of the VLM's existing knowledge base. Furthermore, we develop a spatial-aware question-answering (SA-QA) dataset to explicitly teach the model advanced 3D perception and reasoning capabilities. Extensive experiments on driving benchmarks demonstrate that LVLDrive achieves superior performance compared to vision-only counterparts across scene understanding, metric spatial perception, and reliable driving decision-making. Our work highlights the necessity of explicit 3D metric data for building trustworthy VLM-based autonomous systems.
Auto-Vocabulary Segmentation for LiDAR Points
Jun 13, 2024



Existing perception methods for autonomous driving fall short of recognizing unknown entities not covered in the training data. Open-vocabulary methods offer promising capabilities in detecting any object but are limited by user-specified queries representing target classes. We propose AutoVoc3D, a framework for automatic object class recognition and open-ended segmentation. Evaluation on nuScenes showcases AutoVoc3D's ability to generate precise semantic classes and accurate point-wise segmentation. Moreover, we introduce Text-Point Semantic Similarity, a new metric to assess the semantic similarity between text and point cloud without eliminating novel classes.
T-MAE: Temporal Masked Autoencoders for Point Cloud Representation Learning
Dec 15, 2023



The scarcity of annotated data in outdoor point cloud segmentation poses a significant obstacle in harnessing the modeling capabilities of advanced networks like transformers. Consequently, scholars have been actively investigating efficacious self-supervised pre-training strategies, e.g. contrasting learning and reconstruction-based pretext tasks. Nevertheless, temporal information, which is inherent in the LiDAR point cloud sequence, is consistently disregarded. To better utilize this property, we propose an effective pre-training strategy, namely Temporal Masked AutoEncoders (T-MAE), which takes as input temporally adjacent frames and learns temporal dependency. A SiamWCA backbone, containing a Siamese encoder and a window-based cross-attention (WCA) module, is established for the two-frame input. Taking into account that the motion of an ego-vehicle alters the illumination angles of the same instance, temporal modeling also serves as a robust and natural data augmentation, enhancing the comprehension of target objects. Moreover, instead of utilizing consecutive frames, it is more cost-effective and powerful by using distant historical frames. SiamWCA is a powerful architecture but heavily relies on annotated data. With our T-MAE pre-training strategy, we achieve the best performance on the Waymo dataset among self-supervised learning methods. Comprehensive experiments are conducted to validate all components of our proposal. Upon acceptance, the source code will be made accessible.
APNet: Urban-level Scene Segmentation of Aerial Images and Point Clouds
Sep 29, 2023In this paper, we focus on semantic segmentation method for point clouds of urban scenes. Our fundamental concept revolves around the collaborative utilization of diverse scene representations to benefit from different context information and network architectures. To this end, the proposed network architecture, called APNet, is split into two branches: a point cloud branch and an aerial image branch which input is generated from a point cloud. To leverage the different properties of each branch, we employ a geometry-aware fusion module that is learned to combine the results of each branch. Additional separate losses for each branch avoid that one branch dominates the results, ensure the best performance for each branch individually and explicitly define the input domain of the fusion network assuring it only performs data fusion. Our experiments demonstrate that the fusion output consistently outperforms the individual network branches and that APNet achieves state-of-the-art performance of 65.2 mIoU on the SensatUrban dataset. Upon acceptance, the source code will be made accessible.
Personal Fixations-Based Object Segmentation with Object Localization and Boundary Preservation
Jan 22, 2021

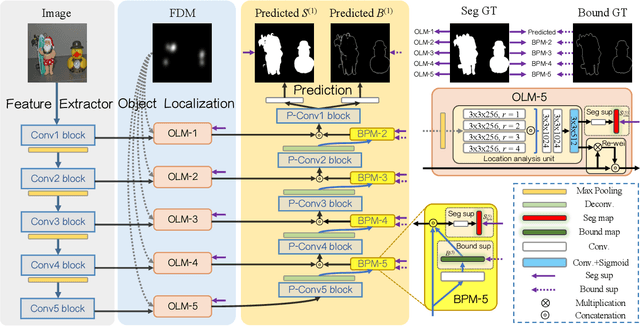

As a natural way for human-computer interaction, fixation provides a promising solution for interactive image segmentation. In this paper, we focus on Personal Fixations-based Object Segmentation (PFOS) to address issues in previous studies, such as the lack of appropriate dataset and the ambiguity in fixations-based interaction. In particular, we first construct a new PFOS dataset by carefully collecting pixel-level binary annotation data over an existing fixation prediction dataset, such dataset is expected to greatly facilitate the study along the line. Then, considering characteristics of personal fixations, we propose a novel network based on Object Localization and Boundary Preservation (OLBP) to segment the gazed objects. Specifically, the OLBP network utilizes an Object Localization Module (OLM) to analyze personal fixations and locates the gazed objects based on the interpretation. Then, a Boundary Preservation Module (BPM) is designed to introduce additional boundary information to guard the completeness of the gazed objects. Moreover, OLBP is organized in the mixed bottom-up and top-down manner with multiple types of deep supervision. Extensive experiments on the constructed PFOS dataset show the superiority of the proposed OLBP network over 17 state-of-the-art methods, and demonstrate the effectiveness of the proposed OLM and BPM components. The constructed PFOS dataset and the proposed OLBP network are available at https://github.com/MathLee/OLBPNet4PFOS.