 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Foundation Models via Knowledge Distillation in Multi-Object Tracking: Distilling DINOv2 Features to FairMOT
Jul 25, 2024Multiple Object Tracking (MOT) is a computer vision task that has been employed in a variety of sectors. Some common limitations in MOT are varying object appearances, occlusions, or crowded scenes. To address these challenges, machine learning methods have been extensively deployed, leveraging large datasets, sophisticated models, and substantial computational resources. Due to practical limitations, access to the above is not always an option. However, with the recent release of foundation models by prominent AI companies, pretrained models have been trained on vast datasets and resources using state-of-the-art methods. This work tries to leverage one such foundation model, called DINOv2, through using knowledge distillation. The proposed method uses a teacher-student architecture, where DINOv2 is the teacher and the FairMOT backbone HRNetv2 W18 is the student. The results imply that although the proposed method shows improvements in certain scenarios, it does not consistently outperform the original FairMOT model. These findings highlight the potential and limitations of applying foundation models in knowledge
MARINE: A Computer Vision Model for Detecting Rare Predator-Prey Interactions in Animal Videos
Jul 25, 2024

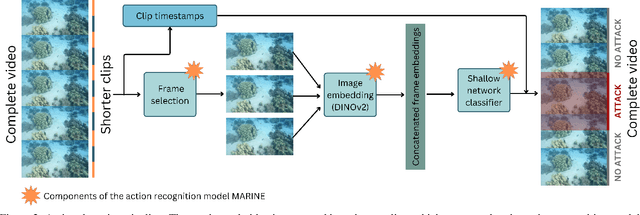
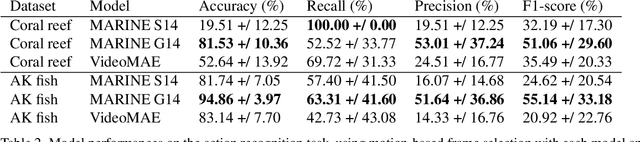
Encounters between predator and prey play an essential role in ecosystems, but their rarity makes them difficult to detect in video recordings. Although advances in action recognition (AR) and temporal action detection (AD), especially transformer-based models and vision foundation models, have achieved high performance on human action datasets, animal videos remain relatively under-researched. This thesis addresses this gap by proposing the model MARINE, which utilizes motion-based frame selection designed for fast animal actions and DINOv2 feature extraction with a trainable classification head for action recognition. MARINE outperforms VideoMAE in identifying predator attacks in videos of fish, both on a small and specific coral reef dataset (81.53\% against 52.64\% accuracy), and on a subset of the more extensive Animal Kingdom dataset (94.86\% against 83.14\% accuracy). In a multi-label setting on a representative sample of Animal Kingdom, MARINE achieves 23.79\% mAP, positioning it mid-field among existing benchmarks. Furthermore, in an AD task on the coral reef dataset, MARINE achieves 80.78\% AP (against VideoMAE's 34.89\%) although at a lowered t-IoU threshold of 25\%. Therefore, despite room for improvement, MARINE offers an effective starter framework to apply to AR and AD tasks on animal recordings and thus contribute to the study of natural ecosystems.
Auto-Vocabulary Segmentation for LiDAR Points
Jun 13, 2024



Existing perception methods for autonomous driving fall short of recognizing unknown entities not covered in the training data. Open-vocabulary methods offer promising capabilities in detecting any object but are limited by user-specified queries representing target classes. We propose AutoVoc3D, a framework for automatic object class recognition and open-ended segmentation. Evaluation on nuScenes showcases AutoVoc3D's ability to generate precise semantic classes and accurate point-wise segmentation. Moreover, we introduce Text-Point Semantic Similarity, a new metric to assess the semantic similarity between text and point cloud without eliminating novel classes.