 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating transformers in the decomposition of polygonal shapes as point collections
Paper and Code
Aug 17, 2021

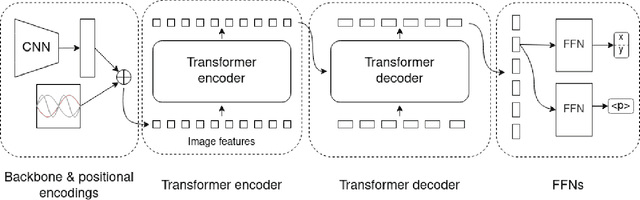

Transformers can generate predictions in two approaches: 1. auto-regressively by conditioning each sequence element on the previous ones, or 2. directly produce an output sequences in parallel. While research has mostly explored upon this difference on sequential tasks in NLP, we study the difference between auto-regressive and parallel prediction on visual set prediction tasks, and in particular on polygonal shapes in images because polygons are representative of numerous types of objects, such as buildings or obstacles for aerial vehicles. This is challenging for deep learning architectures as a polygon can consist of a varying carnality of points. We provide evidence on the importance of natural orders for Transformers, and show the benefit of decomposing complex polygons into collections of points in an auto-regressive manner.