 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural Dropout for Model Width Compression
Paper and Code
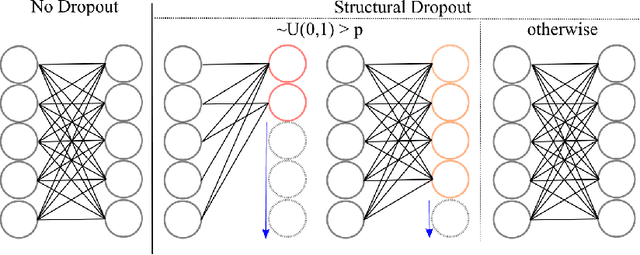

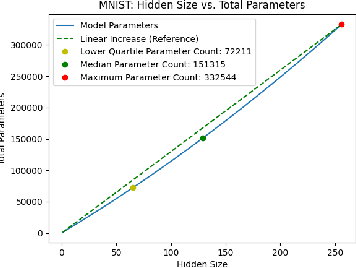
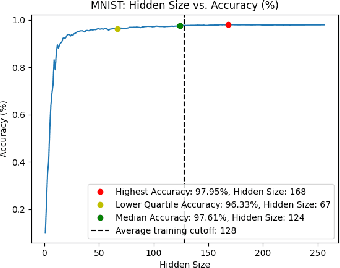
Existing ML models are known to be highly over-parametrized, and use significantly more resources than required for a given task. Prior work has explored compressing models offline, such as by distilling knowledge from larger models into much smaller ones. This is effective for compression, but does not give an empirical method for measuring how much the model can be compressed, and requires additional training for each compressed model. We propose a method that requires only a single training session for the original model and a set of compressed models. The proposed approach is a "structural" dropout that prunes all elements in the hidden state above a randomly chosen index, forcing the model to learn an importance ordering over its features. After learning this ordering, at inference time unimportant features can be pruned while retaining most accuracy, reducing parameter size significantly. In this work, we focus on Structural Dropout for fully-connected layers, but the concept can be applied to any kind of layer with unordered features, such as convolutional or attention layers. Structural Dropout requires no additional pruning/retraining, but requires additional validation for each possible hidden sizes. At inference time, a non-expert can select a memory versus accuracy trade-off that best suits their needs, across a wide range of highly compressed versus more accurate models.