 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFailure Tolerant Training with Persistent Memory Disaggregation over CXL
Jan 20, 2023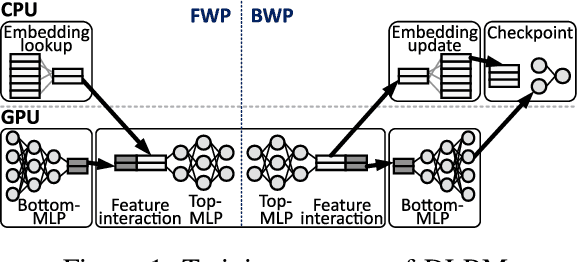

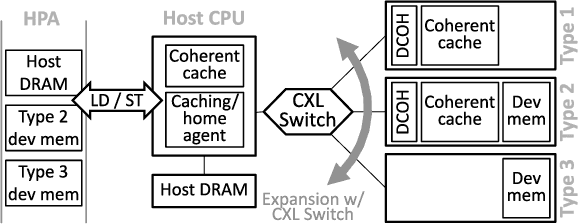

This paper proposes TRAININGCXL that can efficiently process large-scale recommendation datasets in the pool of disaggregated memory while making training fault tolerant with low overhead. To this end, i) we integrate persistent memory (PMEM) and GPU into a cache-coherent domain as Type-2. Enabling CXL allows PMEM to be directly placed in GPU's memory hierarchy, such that GPU can access PMEM without software intervention. TRAININGCXL introduces computing and checkpointing logic near the CXL controller, thereby training data and managing persistency in an active manner. Considering PMEM's vulnerability, ii) we utilize the unique characteristics of recommendation models and take the checkpointing overhead off the critical path of their training. Lastly, iii) TRAININGCXL employs an advanced checkpointing technique that relaxes the updating sequence of model parameters and embeddings across training batches. The evaluation shows that TRAININGCXL achieves 5.2x training performance improvement and 76% energy savings, compared to the modern PMEM-based recommendation systems.