 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFailure Tolerant Training with Persistent Memory Disaggregation over CXL
Jan 20, 2023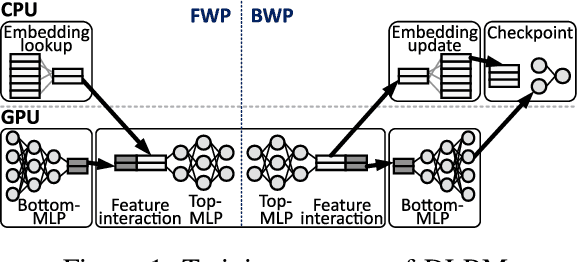

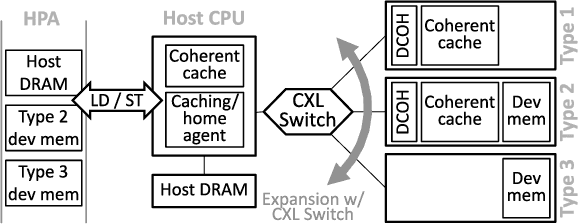

This paper proposes TRAININGCXL that can efficiently process large-scale recommendation datasets in the pool of disaggregated memory while making training fault tolerant with low overhead. To this end, i) we integrate persistent memory (PMEM) and GPU into a cache-coherent domain as Type-2. Enabling CXL allows PMEM to be directly placed in GPU's memory hierarchy, such that GPU can access PMEM without software intervention. TRAININGCXL introduces computing and checkpointing logic near the CXL controller, thereby training data and managing persistency in an active manner. Considering PMEM's vulnerability, ii) we utilize the unique characteristics of recommendation models and take the checkpointing overhead off the critical path of their training. Lastly, iii) TRAININGCXL employs an advanced checkpointing technique that relaxes the updating sequence of model parameters and embeddings across training batches. The evaluation shows that TRAININGCXL achieves 5.2x training performance improvement and 76% energy savings, compared to the modern PMEM-based recommendation systems.
Hardware/Software Co-Programmable Framework for Computational SSDs to Accelerate Deep Learning Service on Large-Scale Graphs
Jan 23, 2022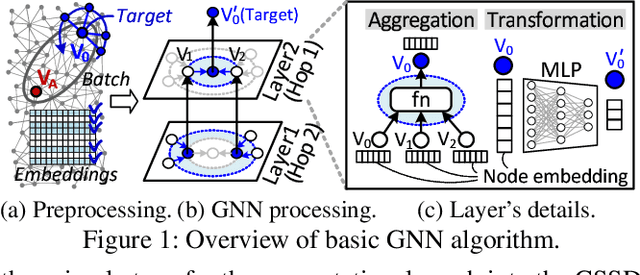

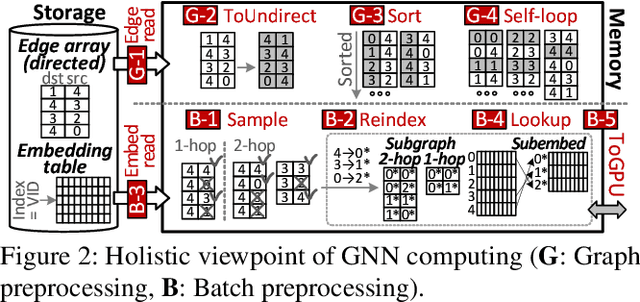

Graph neural networks (GNNs) process large-scale graphs consisting of a hundred billion edges. In contrast to traditional deep learning, unique behaviors of the emerging GNNs are engaged with a large set of graphs and embedding data on storage, which exhibits complex and irregular preprocessing. We propose a novel deep learning framework on large graphs, HolisticGNN, that provides an easy-to-use, near-storage inference infrastructure for fast, energy-efficient GNN processing. To achieve the best end-to-end latency and high energy efficiency, HolisticGNN allows users to implement various GNN algorithms and directly executes them where the actual data exist in a holistic manner. It also enables RPC over PCIe such that the users can simply program GNNs through a graph semantic library without any knowledge of the underlying hardware or storage configurations. We fabricate HolisticGNN's hardware RTL and implement its software on an FPGA-based computational SSD (CSSD). Our empirical evaluations show that the inference time of HolisticGNN outperforms GNN inference services using high-performance modern GPUs by 7.1x while reducing energy consumption by 33.2x, on average.