 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFashion-IQ 2020 Challenge 2nd Place Team's Solution
Paper and Code
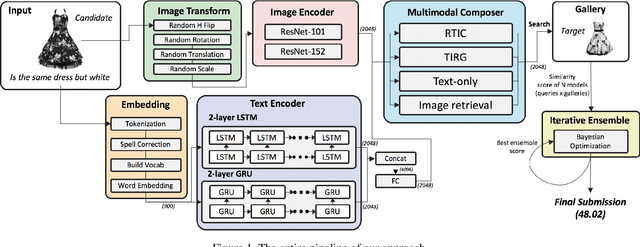
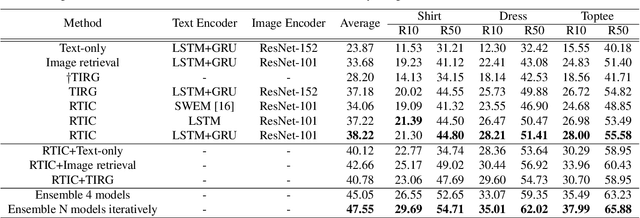
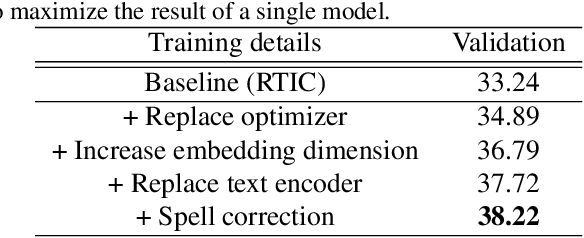

This paper is dedicated to team VAA's approach submitted to the Fashion-IQ challenge in CVPR 2020. Given a pair of the image and the text, we present a novel multimodal composition method, RTIC, that can effectively combine the text and the image modalities into a semantic space. We extract the image and the text features that are encoded by the CNNs and the sequential models (e.g., LSTM or GRU), respectively. To emphasize the meaning of the residual of the feature between the target and candidate, the RTIC is composed of N-blocks with channel-wise attention modules. Then, we add the encoded residual to the feature of the candidate image to obtain a synthesized feature. We also explored an ensemble strategy with variants of models and achieved a significant boost in performance comparing to the best single model. Finally, our approach achieved 2nd place in the Fashion-IQ 2020 Challenge with a test score of 48.02 on the leaderboard.