 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Distilled Hashing for Deep Image Retrieval
Paper and Code
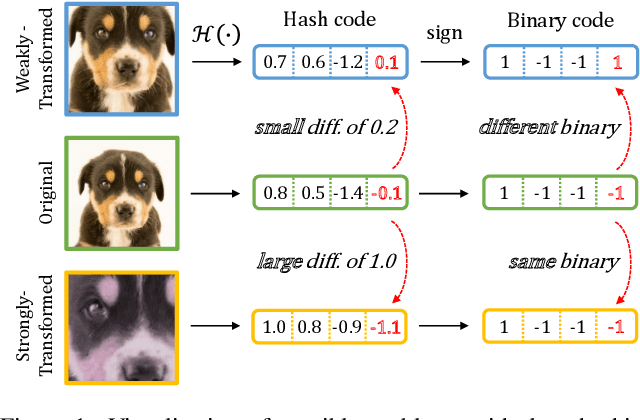

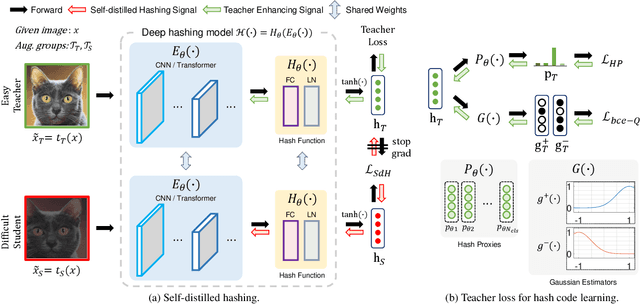

In hash-based image retrieval systems, the transformed input from the original usually generates different codes, deteriorating the retrieval accuracy. To mitigate this issue, data augmentation can be applied during training. However, even if the augmented samples of one content are similar in real space, the quantization can scatter them far away in Hamming space. This results in representation discrepancies that can impede training and degrade performance. In this work, we propose a novel self-distilled hashing scheme to minimize the discrepancy while exploiting the potential of augmented data. By transferring the hash knowledge of the weakly-transformed samples to the strong ones, we make the hash code insensitive to various transformations. We also introduce hash proxy-based similarity learning and binary cross entropy-based quantization loss to provide fine quality hash codes. Ultimately, we construct a deep hashing framework that generates discriminative hash codes. Extensive experiments on benchmarks verify that our self-distillation improves the existing deep hashing approaches, and our framework achieves state-of-the-art retrieval results. The code will be released soon.