 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHMS: Hierarchical Modality Selection for Efficient Video Recognition
Paper and Code
Apr 21, 2021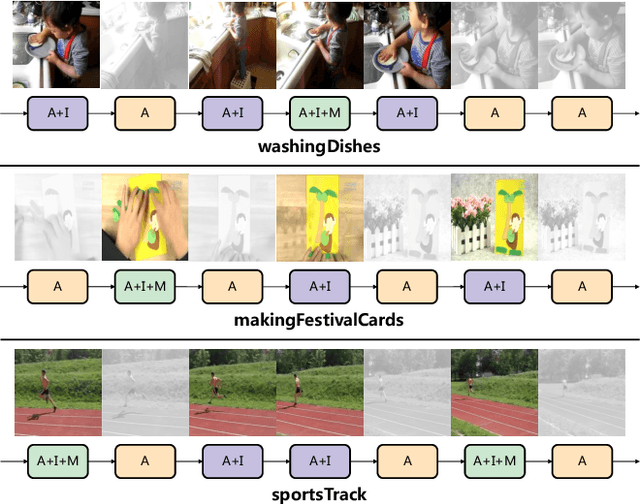



Videos are multimodal in nature. Conventional video recognition pipelines typically fuse multimodal features for improved performance. However, this is not only computationally expensive but also neglects the fact that different videos rely on different modalities for predictions. This paper introduces Hierarchical Modality Selection (HMS), a simple yet efficient multimodal learning framework for efficient video recognition. HMS operates on a low-cost modality, i.e., audio clues, by default, and dynamically decides on-the-fly whether to use computationally-expensive modalities, including appearance and motion clues, on a per-input basis. This is achieved by the collaboration of three LSTMs that are organized in a hierarchical manner. In particular, LSTMs that operate on high-cost modalities contain a gating module, which takes as inputs lower-level features and historical information to adaptively determine whether to activate its corresponding modality; otherwise it simply reuses historical information. We conduct extensive experiments on two large-scale video benchmarks, FCVID and ActivityNet, and the results demonstrate the proposed approach can effectively explore multimodal information for improved classification performance while requiring much less computation.