 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Single-View 3D Reconstruction via Prototype Shape Priors
Paper and Code
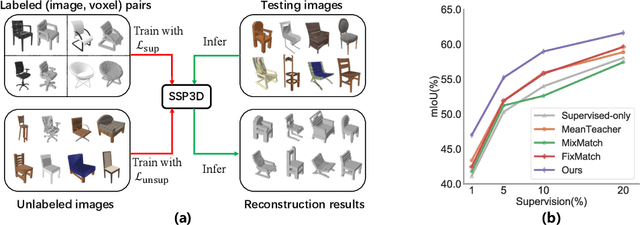
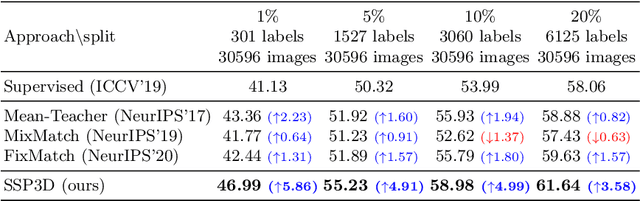

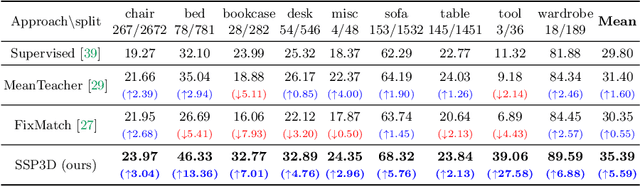
The performance of existing single-view 3D reconstruction methods heavily relies on large-scale 3D annotations. However, such annotations are tedious and expensive to collect. Semi-supervised learning serves as an alternative way to mitigate the need for manual labels, but remains unexplored in 3D reconstruction. Inspired by the recent success of semi-supervised image classification tasks, we propose SSP3D, a semi-supervised framework for 3D reconstruction. In particular, we introduce an attention-guided prototype shape prior module for guiding realistic object reconstruction. We further introduce a discriminator-guided module to incentivize better shape generation, as well as a regularizer to tolerate noisy training samples. On the ShapeNet benchmark, the proposed approach outperforms previous supervised methods by clear margins under various labeling ratios, (i.e., 1%, 5% , 10% and 20%). Moreover, our approach also performs well when transferring to real-world Pix3D datasets under labeling ratios of 10%. We also demonstrate our method could transfer to novel categories with few novel supervised data. Experiments on the popular ShapeNet dataset show that our method outperforms the zero-shot baseline by over 12% and we also perform rigorous ablations and analysis to validate our approach.