 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Video Transformers with Spatial-Temporal Token Selection
Paper and Code

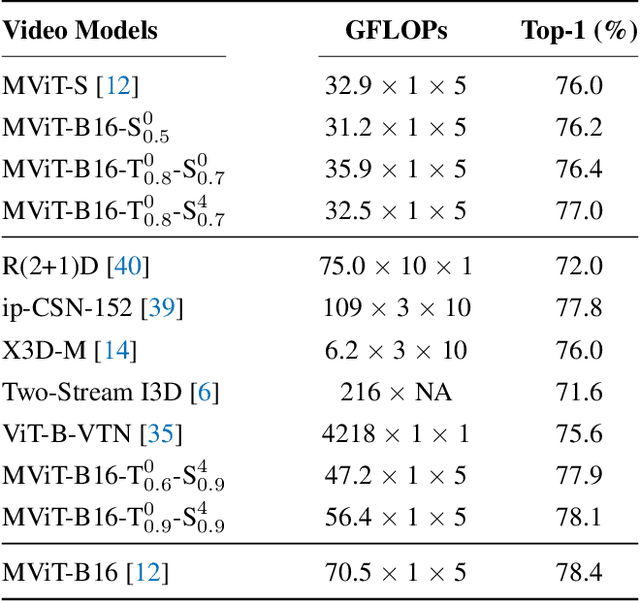
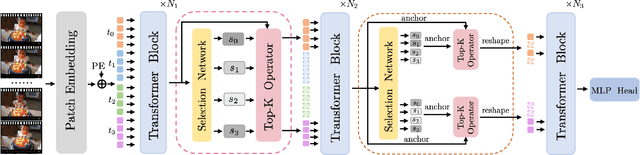
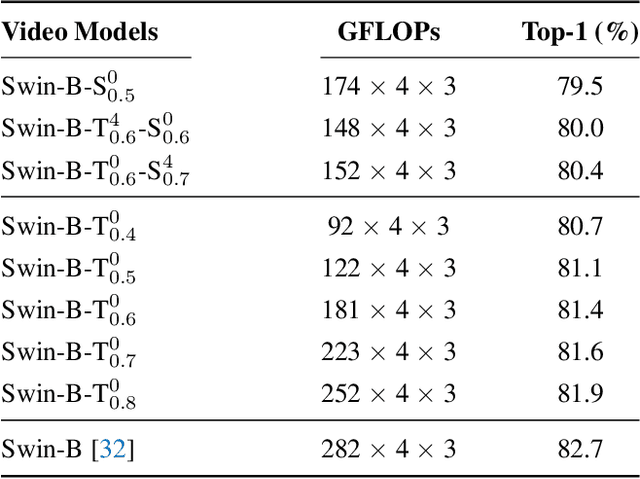
Video transformers have achieved impressive results on major video recognition benchmarks, however they suffer from high computational cost. In this paper, we present STTS, a token selection framework that dynamically selects a few informative tokens in both temporal and spatial dimensions conditioned on input video samples. Specifically, we formulate token selection as a ranking problem, which estimates the importance of each token through a lightweight selection network and only those with top scores will be used for downstream evaluation. In the temporal dimension, we keep the frames that are most relevant for recognizing action categories, while in the spatial dimension, we identify the most discriminative region in feature maps without affecting spatial context used in a hierarchical way in most video transformers. Since the decision of token selection is non-differentiable, we employ a perturbed-maximum based differentiable Top-K operator for end-to-end training. We conduct extensive experiments on Kinetics-400 with a recently introduced video transformer backbone, MViT. Our framework achieves similar results while requiring 20% less computation. We also demonstrate that our approach is compatible with other transformer architectures.