 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Role of Iterative Computation in Reinforcement Learning
Feb 17, 2026How does the amount of compute available to a reinforcement learning (RL) policy affect its learning? Can policies using a fixed amount of parameters, still benefit from additional compute? The standard RL framework does not provide a language to answer these questions formally. Empirically, deep RL policies are often parameterized as neural networks with static architectures, conflating the amount of compute and the number of parameters. In this paper, we formalize compute bounded policies and prove that policies which use more compute can solve problems and generalize to longer-horizon tasks that are outside the scope of policies with less compute. Building on prior work in algorithmic learning and model-free planning, we propose a minimal architecture that can use a variable amount of compute. Our experiments complement our theory. On a set 31 different tasks spanning online and offline RL, we show that $(1)$ this architecture achieves stronger performance simply by using more compute, and $(2)$ stronger generalization on longer-horizon test tasks compared to standard feedforward networks or deep residual network using up to 5 times more parameters.
On Computation and Reinforcement Learning
Feb 05, 2026How does the amount of compute available to a reinforcement learning (RL) policy affect its learning? Can policies using a fixed amount of parameters, still benefit from additional compute? The standard RL framework does not provide a language to answer these questions formally. Empirically, deep RL policies are often parameterized as neural networks with static architectures, conflating the amount of compute and the number of parameters. In this paper, we formalize compute bounded policies and prove that policies which use more compute can solve problems and generalize to longer-horizon tasks that are outside the scope of policies with less compute. Building on prior work in algorithmic learning and model-free planning, we propose a minimal architecture that can use a variable amount of compute. Our experiments complement our theory. On a set 31 different tasks spanning online and offline RL, we show that $(1)$ this architecture achieves stronger performance simply by using more compute, and $(2)$ stronger generalization on longer-horizon test tasks compared to standard feedforward networks or deep residual network using up to 5 times more parameters.
Normalizing Flows are Capable Models for RL
May 29, 2025Modern reinforcement learning (RL) algorithms have found success by using powerful probabilistic models, such as transformers, energy-based models, and diffusion/flow-based models. To this end, RL researchers often choose to pay the price of accommodating these models into their algorithms -- diffusion models are expressive, but are computationally intensive due to their reliance on solving differential equations, while autoregressive transformer models are scalable but typically require learning discrete representations. Normalizing flows (NFs), by contrast, seem to provide an appealing alternative, as they enable likelihoods and sampling without solving differential equations or autoregressive architectures. However, their potential in RL has received limited attention, partly due to the prevailing belief that normalizing flows lack sufficient expressivity. We show that this is not the case. Building on recent work in NFs, we propose a single NF architecture which integrates seamlessly into RL algorithms, serving as a policy, Q-function, and occupancy measure. Our approach leads to much simpler algorithms, and achieves higher performance in imitation learning, offline, goal conditioned RL and unsupervised RL.
Closing the Gap between TD Learning and Supervised Learning -- A Generalisation Point of View
Jan 20, 2024Some reinforcement learning (RL) algorithms can stitch pieces of experience to solve a task never seen before during training. This oft-sought property is one of the few ways in which RL methods based on dynamic-programming differ from RL methods based on supervised-learning (SL). Yet, certain RL methods based on off-the-shelf SL algorithms achieve excellent results without an explicit mechanism for stitching; it remains unclear whether those methods forgo this important stitching property. This paper studies this question for the problems of achieving a target goal state and achieving a target return value. Our main result is to show that the stitching property corresponds to a form of combinatorial generalization: after training on a distribution of (state, goal) pairs, one would like to evaluate on (state, goal) pairs not seen together in the training data. Our analysis shows that this sort of generalization is different from i.i.d. generalization. This connection between stitching and generalisation reveals why we should not expect SL-based RL methods to perform stitching, even in the limit of large datasets and models. Based on this analysis, we construct new datasets to explicitly test for this property, revealing that SL-based methods lack this stitching property and hence fail to perform combinatorial generalization. Nonetheless, the connection between stitching and combinatorial generalisation also suggests a simple remedy for improving generalisation in SL: data augmentation. We propose a temporal data augmentation and demonstrate that adding it to SL-based methods enables them to successfully complete tasks not seen together during training. On a high level, this connection illustrates the importance of combinatorial generalization for data efficiency in time-series data beyond tasks beyond RL, like audio, video, or text.
Searching for High-Value Molecules Using Reinforcement Learning and Transformers
Oct 04, 2023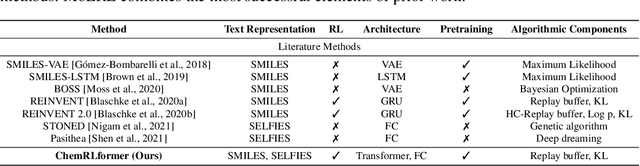
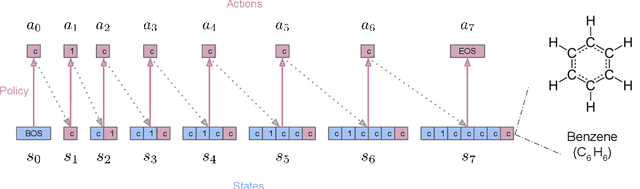
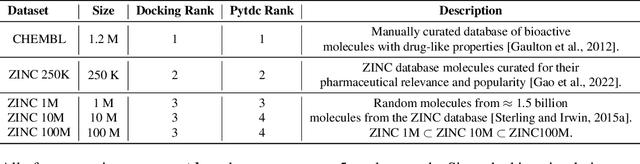
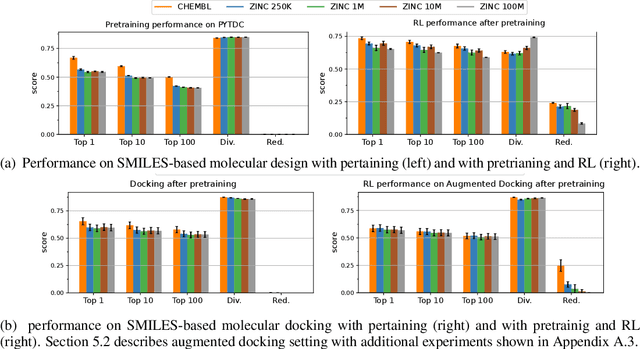
Reinforcement learning (RL) over text representations can be effective for finding high-value policies that can search over graphs. However, RL requires careful structuring of the search space and algorithm design to be effective in this challenge. Through extensive experiments, we explore how different design choices for text grammar and algorithmic choices for training can affect an RL policy's ability to generate molecules with desired properties. We arrive at a new RL-based molecular design algorithm (ChemRLformer) and perform a thorough analysis using 25 molecule design tasks, including computationally complex protein docking simulations. From this analysis, we discover unique insights in this problem space and show that ChemRLformer achieves state-of-the-art performance while being more straightforward than prior work by demystifying which design choices are actually helpful for text-based molecule design.
Simplifying Model-based RL: Learning Representations, Latent-space Models, and Policies with One Objective
Sep 18, 2022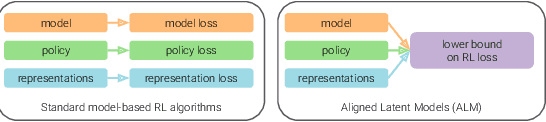

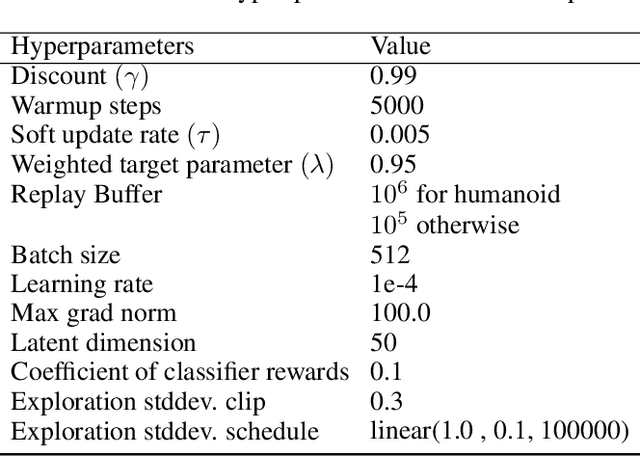
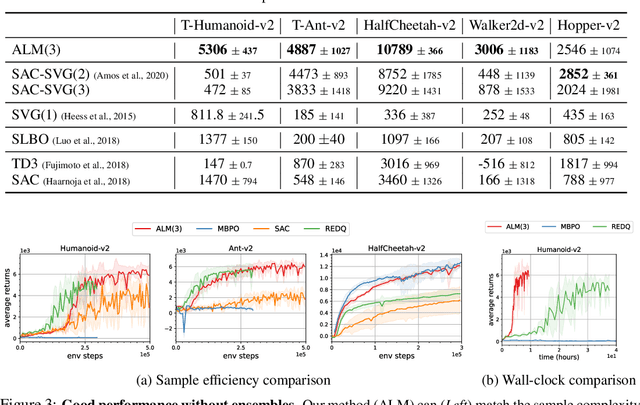
While reinforcement learning (RL) methods that learn an internal model of the environment have the potential to be more sample efficient than their model-free counterparts, learning to model raw observations from high dimensional sensors can be challenging. Prior work has addressed this challenge by learning low-dimensional representation of observations through auxiliary objectives, such as reconstruction or value prediction. However, the alignment between these auxiliary objectives and the RL objective is often unclear. In this work, we propose a single objective which jointly optimizes a latent-space model and policy to achieve high returns while remaining self-consistent. This objective is a lower bound on expected returns. Unlike prior bounds for model-based RL on policy exploration or model guarantees, our bound is directly on the overall RL objective. We demonstrate that the resulting algorithm matches or improves the sample-efficiency of the best prior model-based and model-free RL methods. While such sample efficient methods typically are computationally demanding, our method attains the performance of SAC in about 50\% less wall-clock time.