 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Predictive Representations for Combinatorial Generalization in Behavioral Cloning
Jun 11, 2025Behavioral cloning (BC) methods trained with supervised learning (SL) are an effective way to learn policies from human demonstrations in domains like robotics. Goal-conditioning these policies enables a single generalist policy to capture diverse behaviors contained within an offline dataset. While goal-conditioned behavior cloning (GCBC) methods can perform well on in-distribution training tasks, they do not necessarily generalize zero-shot to tasks that require conditioning on novel state-goal pairs, i.e. combinatorial generalization. In part, this limitation can be attributed to a lack of temporal consistency in the state representation learned by BC; if temporally related states are encoded to similar latent representations, then the out-of-distribution gap for novel state-goal pairs would be reduced. Hence, encouraging this temporal consistency in the representation space should facilitate combinatorial generalization. Successor representations, which encode the distribution of future states visited from the current state, nicely encapsulate this property. However, previous methods for learning successor representations have relied on contrastive samples, temporal-difference (TD) learning, or both. In this work, we propose a simple yet effective representation learning objective, $\text{BYOL-}\gamma$ augmented GCBC, which is not only able to theoretically approximate the successor representation in the finite MDP case without contrastive samples or TD learning, but also, results in competitive empirical performance across a suite of challenging tasks requiring combinatorial generalization.
Surprise-Adaptive Intrinsic Motivation for Unsupervised Reinforcement Learning
May 27, 2024



Both entropy-minimizing and entropy-maximizing (curiosity) objectives for unsupervised reinforcement learning (RL) have been shown to be effective in different environments, depending on the environment's level of natural entropy. However, neither method alone results in an agent that will consistently learn intelligent behavior across environments. In an effort to find a single entropy-based method that will encourage emergent behaviors in any environment, we propose an agent that can adapt its objective online, depending on the entropy conditions by framing the choice as a multi-armed bandit problem. We devise a novel intrinsic feedback signal for the bandit, which captures the agent's ability to control the entropy in its environment. We demonstrate that such agents can learn to control entropy and exhibit emergent behaviors in both high- and low-entropy regimes and can learn skillful behaviors in benchmark tasks. Videos of the trained agents and summarized findings can be found on our project page https://sites.google.com/view/surprise-adaptive-agents
Searching for High-Value Molecules Using Reinforcement Learning and Transformers
Oct 04, 2023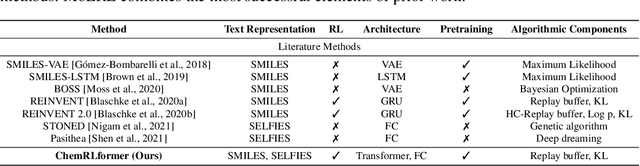
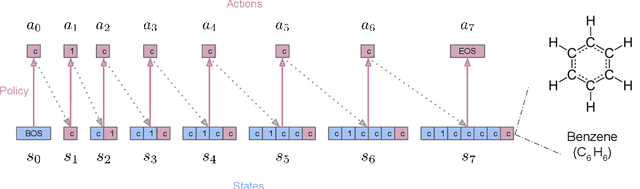
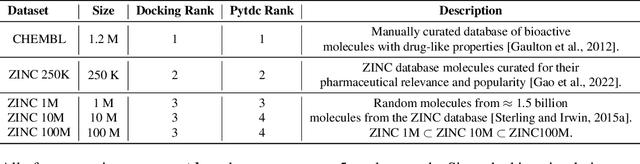
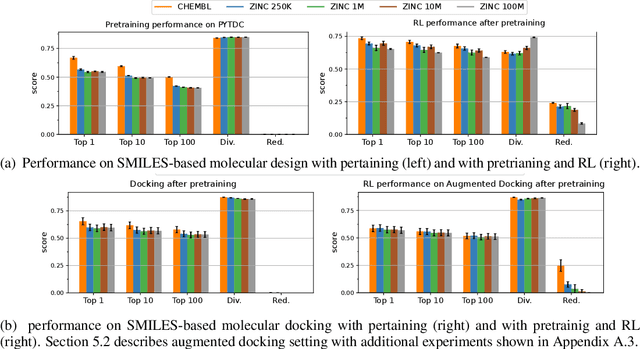
Reinforcement learning (RL) over text representations can be effective for finding high-value policies that can search over graphs. However, RL requires careful structuring of the search space and algorithm design to be effective in this challenge. Through extensive experiments, we explore how different design choices for text grammar and algorithmic choices for training can affect an RL policy's ability to generate molecules with desired properties. We arrive at a new RL-based molecular design algorithm (ChemRLformer) and perform a thorough analysis using 25 molecule design tasks, including computationally complex protein docking simulations. From this analysis, we discover unique insights in this problem space and show that ChemRLformer achieves state-of-the-art performance while being more straightforward than prior work by demystifying which design choices are actually helpful for text-based molecule design.