 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDNS: Determinantal Point Process Based Neural Network Sampler for Ensemble Reinforcement Learning
Feb 06, 2022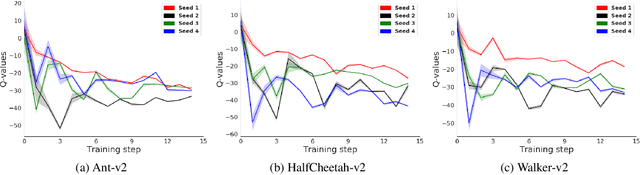
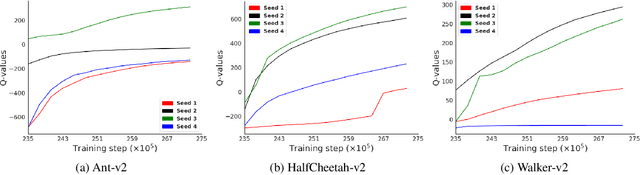
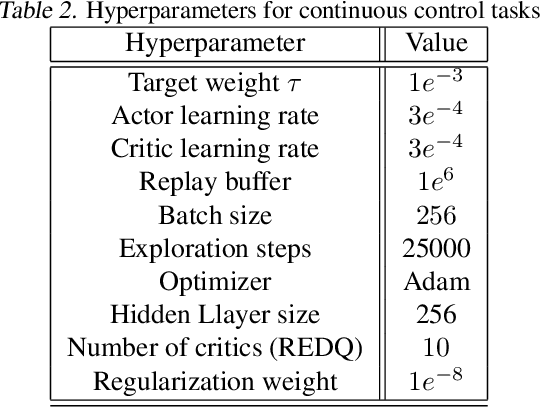
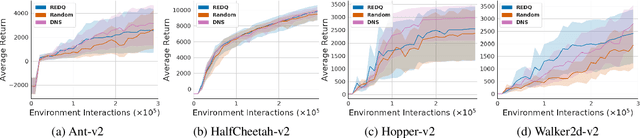
Application of ensemble of neural networks is becoming an imminent tool for advancing the state-of-the-art in deep reinforcement learning algorithms. However, training these large numbers of neural networks in the ensemble has an exceedingly high computation cost which may become a hindrance in training large-scale systems. In this paper, we propose DNS: a Determinantal Point Process based Neural Network Sampler that specifically uses k-dpp to sample a subset of neural networks for backpropagation at every training step thus significantly reducing the training time and computation cost. We integrated DNS in REDQ for continuous control tasks and evaluated on MuJoCo environments. Our experiments show that DNS augmented REDQ outperforms baseline REDQ in terms of average cumulative reward and achieves this using less than 50% computation when measured in FLOPS.
Minimizing Communication while Maximizing Performance in Multi-Agent Reinforcement Learning
Jun 18, 2021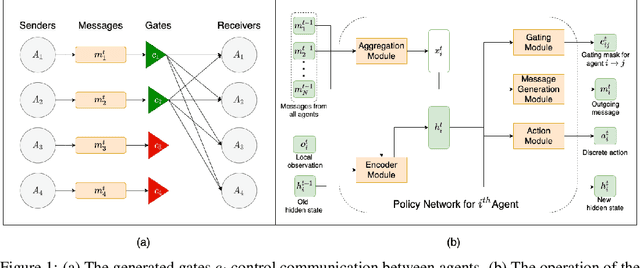

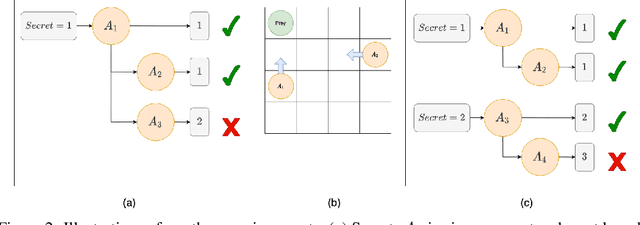
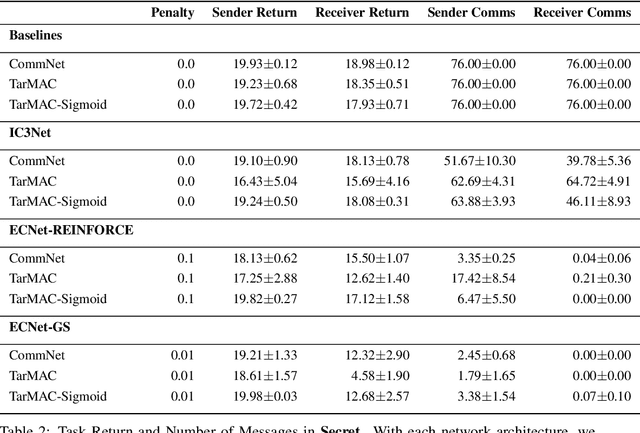
Inter-agent communication can significantly increase performance in multi-agent tasks that require co-ordination to achieve a shared goal. Prior work has shown that it is possible to learn inter-agent communication protocols using multi-agent reinforcement learning and message-passing network architectures. However, these models use an unconstrained broadcast communication model, in which an agent communicates with all other agents at every step, even when the task does not require it. In real-world applications, where communication may be limited by system constraints like bandwidth, power and network capacity, one might need to reduce the number of messages that are sent. In this work, we explore a simple method of minimizing communication while maximizing performance in multi-task learning: simultaneously optimizing a task-specific objective and a communication penalty. We show that the objectives can be optimized using Reinforce and the Gumbel-Softmax reparameterization. We introduce two techniques to stabilize training: 50% training and message forwarding. Training with the communication penalty on only 50% of the episodes prevents our models from turning off their outgoing messages. Second, repeating messages received previously helps models retain information, and further improves performance. With these techniques, we show that we can reduce communication by 75% with no loss of performance.
Learning Intrinsic Symbolic Rewards in Reinforcement Learning
Oct 09, 2020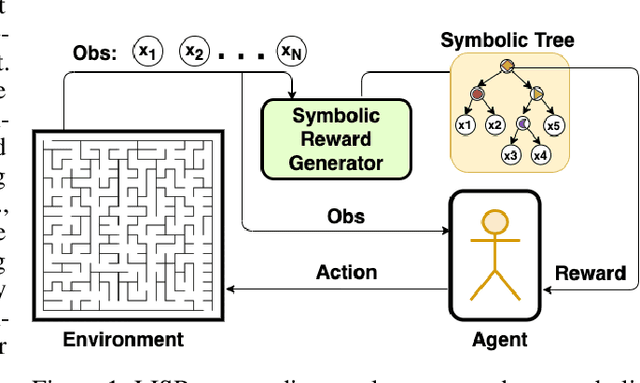
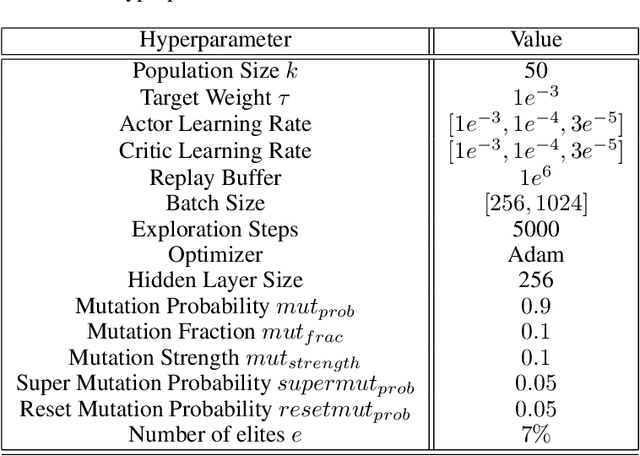
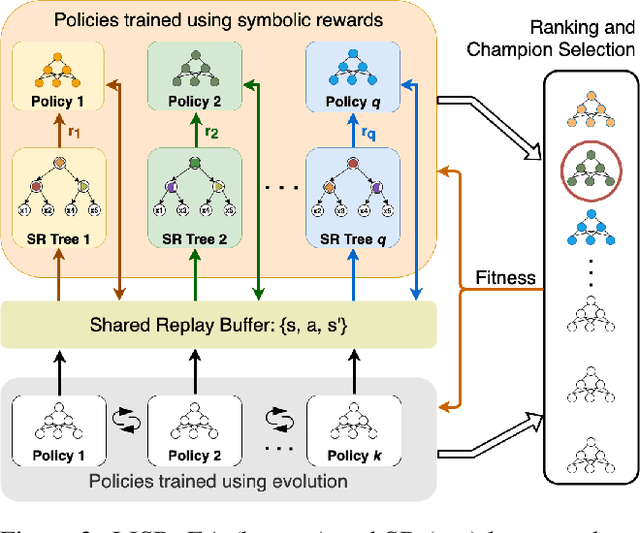
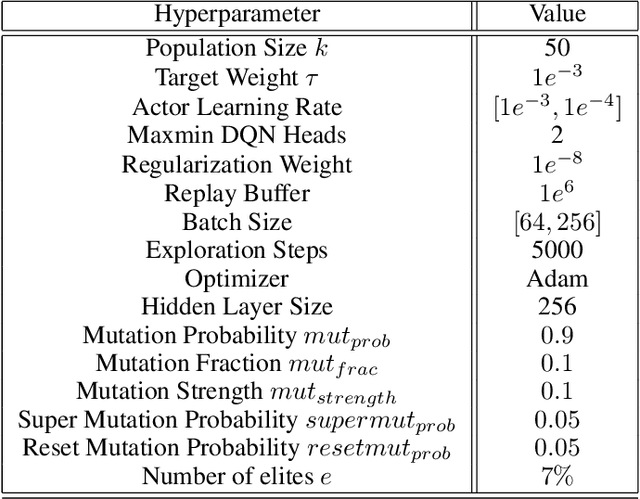
Learning effective policies for sparse objectives is a key challenge in Deep Reinforcement Learning (RL). A common approach is to design task-related dense rewards to improve task learnability. While such rewards are easily interpreted, they rely on heuristics and domain expertise. Alternate approaches that train neural networks to discover dense surrogate rewards avoid heuristics, but are high-dimensional, black-box solutions offering little interpretability. In this paper, we present a method that discovers dense rewards in the form of low-dimensional symbolic trees - thus making them more tractable for analysis. The trees use simple functional operators to map an agent's observations to a scalar reward, which then supervises the policy gradient learning of a neural network policy. We test our method on continuous action spaces in Mujoco and discrete action spaces in Atari and Pygame environments. We show that the discovered dense rewards are an effective signal for an RL policy to solve the benchmark tasks. Notably, we significantly outperform a widely used, contemporary neural-network based reward-discovery algorithm in all environments considered.