 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-training for Demographic Classification Using Deep Learning from Label Proportions
Paper and Code
Sep 13, 2017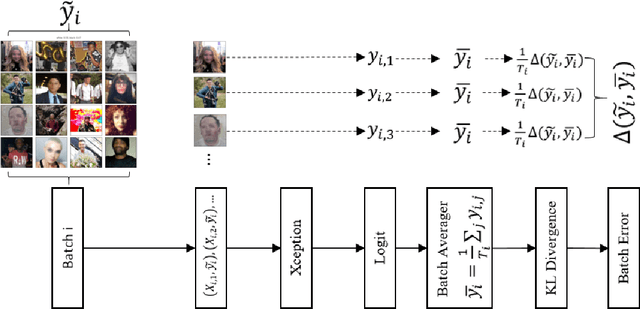


Deep learning algorithms have recently produced state-of-the-art accuracy in many classification tasks, but this success is typically dependent on access to many annotated training examples. For domains without such data, an attractive alternative is to train models with light, or distant supervision. In this paper, we introduce a deep neural network for the Learning from Label Proportion (LLP) setting, in which the training data consist of bags of unlabeled instances with associated label distributions for each bag. We introduce a new regularization layer, Batch Averager, that can be appended to the last layer of any deep neural network to convert it from supervised learning to LLP. This layer can be implemented readily with existing deep learning packages. To further support domains in which the data consist of two conditionally independent feature views (e.g. image and text), we propose a co-training algorithm that iteratively generates pseudo bags and refits the deep LLP model to improve classification accuracy. We demonstrate our models on demographic attribute classification (gender and race/ethnicity), which has many applications in social media analysis, public health, and marketing. We conduct experiments to predict demographics of Twitter users based on their tweets and profile image, without requiring any user-level annotations for training. We find that the deep LLP approach outperforms baselines for both text and image features separately. Additionally, we find that co-training algorithm improves image and text classification by 4% and 8% absolute F1, respectively. Finally, an ensemble of text and image classifiers further improves the absolute F1 measure by 4% on average.