 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecentralized No-Regret Frequency-Time Scheduling for FMCW Radar Interference Avoidance
Dec 31, 2025Automotive FMCW radars are indispensable to modern ADAS and autonomous-driving systems, but their increasing density has intensified the risk of mutual interference. Existing mitigation techniques, including reactive receiver-side suppression, proactive waveform design, and cooperative scheduling, often face limitations in scalability, reliance on side-channel communication, or degradation of range-Doppler resolution. Building on our earlier work on decentralized Frequency-Domain No-Regret hopping, this paper introduces a unified time-frequency game-theoretic framework that enables radars to adapt across both spectral and temporal resources. We formulate the interference-avoidance problem as a repeated anti-coordination game, in which each radar autonomously updates a mixed strategy over frequency subbands and chirp-level time offsets using regret-minimization dynamics. We show that the proposed Time-Frequency No-Regret Hopping algorithm achieves vanishing external and swap regret, and that the induced empirical play converges to an $\varepsilon$-coarse correlated equilibrium or a correlated equilibrium. Theoretical analysis provides regret bounds in the joint domain, revealing how temporal adaptation implicitly regularizes frequency selection and enhances robustness against asynchronous interference. Numerical experiments with multi-radar scenarios demonstrate substantial improvements in SINR, collision rate, and range-Doppler quality compared with time-frequency random hopping and centralized Nash-based benchmarks.
From Texts to Shields: Convergence of Large Language Models and Cybersecurity
May 01, 2025This report explores the convergence of large language models (LLMs) and cybersecurity, synthesizing interdisciplinary insights from network security, artificial intelligence, formal methods, and human-centered design. It examines emerging applications of LLMs in software and network security, 5G vulnerability analysis, and generative security engineering. The report highlights the role of agentic LLMs in automating complex tasks, improving operational efficiency, and enabling reasoning-driven security analytics. Socio-technical challenges associated with the deployment of LLMs -- including trust, transparency, and ethical considerations -- can be addressed through strategies such as human-in-the-loop systems, role-specific training, and proactive robustness testing. The report further outlines critical research challenges in ensuring interpretability, safety, and fairness in LLM-based systems, particularly in high-stakes domains. By integrating technical advances with organizational and societal considerations, this report presents a forward-looking research agenda for the secure and effective adoption of LLMs in cybersecurity.
A Game-Theoretic Approach for High-Resolution Automotive FMCW Radar Interference Avoidance
Mar 04, 2025
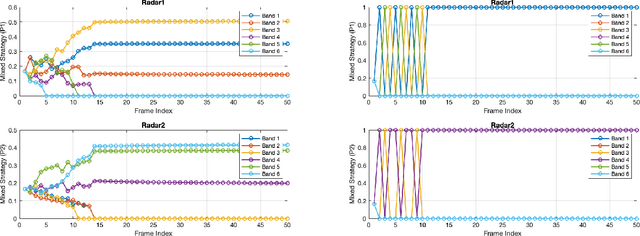
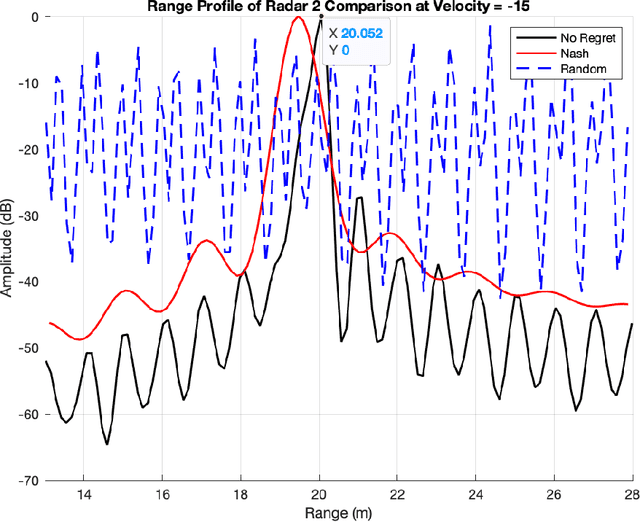
Nonlinear frequency hopping has emerged as a promising approach for mitigating interference and enhancing range resolution in automotive FMCW radar systems. Achieving an optimal balance between high range-resolution and effective interference mitigation remains challenging, especially without centralized frequency scheduling. This paper presents a game-theoretic framework for interference avoidance, in which each radar operates as an independent player, optimizing its performance through decentralized decision-making. We examine two equilibrium concepts--Nash Equilibrium (NE) and Coarse Correlated Equilibrium (CCE)--as strategies for frequency band allocation, with CCE demonstrating particular effectiveness through regret minimization algorithms. We propose two interference avoidance algorithms: Nash Hopping, a model-based approach, and No-Regret Hopping, a model-free adaptive method. Simulation results indicate that both methods effectively reduce interference and enhance the signal-to-interference-plus-noise ratio (SINR). Notably, No-regret Hopping further optimizes frequency spectrum utilization, achieving improved range resolution compared to Nash Hopping.
Meta Stackelberg Game: Robust Federated Learning against Adaptive and Mixed Poisoning Attacks
Oct 22, 2024



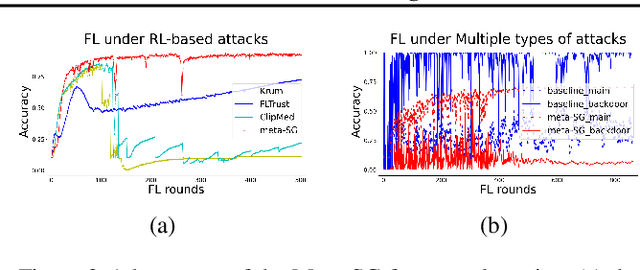
Federated learning (FL) is susceptible to a range of security threats. Although various defense mechanisms have been proposed, they are typically non-adaptive and tailored to specific types of attacks, leaving them insufficient in the face of multiple uncertain, unknown, and adaptive attacks employing diverse strategies. This work formulates adversarial federated learning under a mixture of various attacks as a Bayesian Stackelberg Markov game, based on which we propose the meta-Stackelberg defense composed of pre-training and online adaptation. {The gist is to simulate strong attack behavior using reinforcement learning (RL-based attacks) in pre-training and then design meta-RL-based defense to combat diverse and adaptive attacks.} We develop an efficient meta-learning approach to solve the game, leading to a robust and adaptive FL defense. Theoretically, our meta-learning algorithm, meta-Stackelberg learning, provably converges to the first-order $\varepsilon$-meta-equilibrium point in $O(\varepsilon^{-2})$ gradient iterations with $O(\varepsilon^{-4})$ samples per iteration. Experiments show that our meta-Stackelberg framework performs superbly against strong model poisoning and backdoor attacks of uncertain and unknown types.
Model-Agnostic Zeroth-Order Policy Optimization for Meta-Learning of Ergodic Linear Quadratic Regulators
May 27, 2024
Meta-learning has been proposed as a promising machine learning topic in recent years, with important applications to image classification, robotics, computer games, and control systems. In this paper, we study the problem of using meta-learning to deal with uncertainty and heterogeneity in ergodic linear quadratic regulators. We integrate the zeroth-order optimization technique with a typical meta-learning method, proposing an algorithm that omits the estimation of policy Hessian, which applies to tasks of learning a set of heterogeneous but similar linear dynamic systems. The induced meta-objective function inherits important properties of the original cost function when the set of linear dynamic systems are meta-learnable, allowing the algorithm to optimize over a learnable landscape without projection onto the feasible set. We provide a convergence result for the exact gradient descent process by analyzing the boundedness and smoothness of the gradient for the meta-objective, which justify the proposed algorithm with gradient estimation error being small. We also provide a numerical example to corroborate this perspective.
A First Order Meta Stackelberg Method for Robust Federated Learning
Jul 16, 2023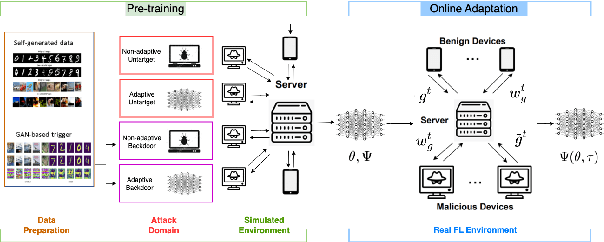
Previous research has shown that federated learning (FL) systems are exposed to an array of security risks. Despite the proposal of several defensive strategies, they tend to be non-adaptive and specific to certain types of attacks, rendering them ineffective against unpredictable or adaptive threats. This work models adversarial federated learning as a Bayesian Stackelberg Markov game (BSMG) to capture the defender's incomplete information of various attack types. We propose meta-Stackelberg learning (meta-SL), a provably efficient meta-learning algorithm, to solve the equilibrium strategy in BSMG, leading to an adaptable FL defense. We demonstrate that meta-SL converges to the first-order $\varepsilon$-equilibrium point in $O(\varepsilon^{-2})$ gradient iterations, with $O(\varepsilon^{-4})$ samples needed per iteration, matching the state of the art. Empirical evidence indicates that our meta-Stackelberg framework performs exceptionally well against potent model poisoning and backdoor attacks of an uncertain nature.
Is Stochastic Mirror Descent Vulnerable to Adversarial Delay Attacks? A Traffic Assignment Resilience Study
Apr 03, 2023\textit{Intelligent Navigation Systems} (INS) are exposed to an increasing number of informational attack vectors, which often intercept through the communication channels between the INS and the transportation network during the data collecting process. To measure the resilience of INS, we use the concept of a Wardrop Non-Equilibrium Solution (WANES), which is characterized by the probabilistic outcome of learning within a bounded number of interactions. By using concentration arguments, we have discovered that any bounded feedback delaying attack only degrades the systematic performance up to order $\tilde{\mathcal{O}}(\sqrt{{d^3}{T^{-1}}})$ along the traffic flow trajectory within the Delayed Mirror Descent (DMD) online-learning framework. This degradation in performance can occur with only mild assumptions imposed. Our result implies that learning-based INS infrastructures can achieve Wardrop Non-equilibrium even when experiencing a certain period of disruption in the information structure. These findings provide valuable insights for designing defense mechanisms against possible jamming attacks across different layers of the transportation ecosystem.